

Now that it's clear how the data is structured and what is contained in the collection, we can get a better understanding by looking at some basic stats.
To get us started, let's invoke the describe function:
julia> describe(iris)The output is as follows:

This function summarizes the columns of the irisDataFrame. If the columns contain numerical data (such as SepalLength), it will compute the minimum, median, mean, and maximum. The number of missing and unique values is also included. The last column reports the type of data stored in the row.
A few other stats are available, including the 25th and the 75th percentile, and the first and the last values. We can ask for them by passing an extra stats argument, in the form of an array of symbols:
julia> describe(iris, stats=[:q25, :q75, :first, :last])The output is as follows:
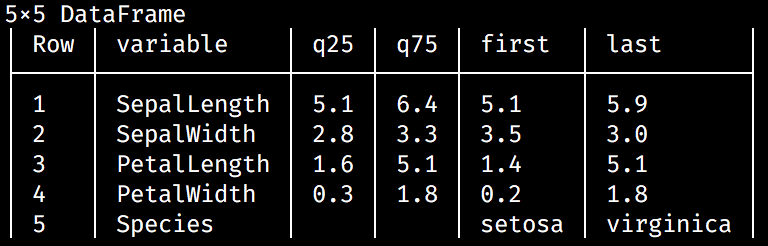
Any combination of stats labels is accepted. These are all the options—:mean, :std, :min, :q25, :median, :q75, ...