TensorFlow represents devices as strings. Here, we will show you how one can manually assign a device for matrix multiplication in TensorFlow. To verify that TensorFlow is indeed using the device (CPU or GPU) specified, we create the session with the log_device_placement flag set to True, namely, config=tf.ConfigProto(log_device_placement=True):
- If you are not sure about the device and want TensorFlow to choose the existing and supported device, you can set the allow_soft_placement flag to True:
config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
- Manually select CPU for operation:
with tf.device('/cpu:0'):
rand_t = tf.random_uniform([50,50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c = tf.matmul(a,b)
init = tf.global_variables_initializer()
sess = tf.Session(config)
sess.run(init)
print(sess.run(c))
-
We get the following output:
We can see that all the devices, in this case, are '/cpu:0'.
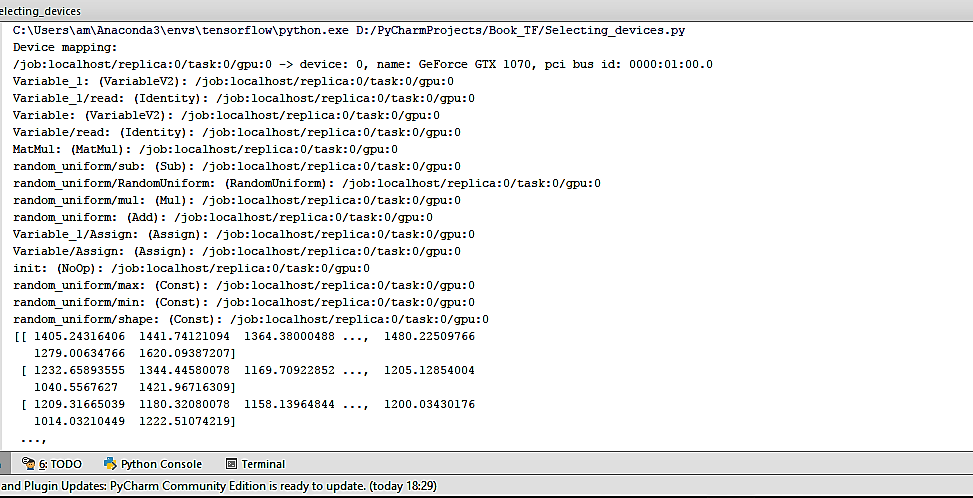
- Manually select a single GPU for operation:
with tf.device('/gpu:0'):
rand_t = tf.random_uniform([50,50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c = tf.matmul(a,b)
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(init)
print(sess.run(c))
- The output now changes to the following:
- The '/cpu:0' after each operation is now replaced by '/gpu:0'.
- Manually select multiple GPUs:
c=[]
for d in ['/gpu:1','/gpu:2']:
with tf.device(d):
rand_t = tf.random_uniform([50, 50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c.append(tf.matmul(a,b))
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))
sess.run(init)
print(sess.run(c))
sess.close()
- In this case, if the system has three GPU devices, then the first set of multiplication will be carried on by '/gpu:1' and the second set by '/gpu:2'.