

We're now going to move onto the second artificial neural network, Convolutional Neural Networks (CNNs). In this section, we're going solve the same MNIST digit classification problem, instead this time using CNNs.
Figure 1.4.1 shows the CNN model that we'll use for the MNIST digit classification, while its implementation is illustrated in Listing 1.4.1. Some changes in the previous model will be needed to implement the CNN model. Instead of having input vector, the input tensor now has new dimensions (height, width, channels) or (image_size, image_size, 1) = (28, 28, 1) for the grayscale MNIST images. Resizing the train and test images will be needed to conform to this input shape requirement.
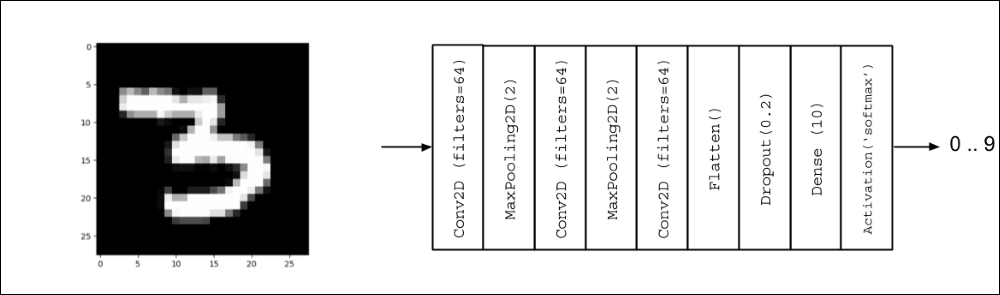
Figure 1.4.1: CNN model for MNIST digit classification
Listing 1.4.1, cnn-mnist-1.4.1.py shows the Keras code for the MNIST digit classification using CNN:
import numpy as np
from keras.models import Sequential
from keras.layers import Activation, Dense, Dropout
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.utils import to_categorical, plot_model
from keras.datasets import mnist
# load mnist dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# compute the number of labels
num_labels = len(np.unique(y_train))
# convert to one-hot vector
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# input image dimensions
image_size = x_train.shape[1]
# resize and normalize
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
# image is processed as is (square grayscale)
input_shape = (image_size, image_size, 1)
batch_size = 128
kernel_size = 3
pool_size = 2
filters = 64
dropout = 0.2
# model is a stack of CNN-ReLU-MaxPooling
model = Sequential()
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu'))
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu'))
model.add(Flatten())
# dropout added as regularizer
model.add(Dropout(dropout))
# output layer is 10-dim one-hot vector
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.summary()
plot_model(model, to_file='cnn-mnist.png', show_shapes=True)
# loss function for one-hot vector
# use of adam optimizer
# accuracy is good metric for classification tasks
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train the network
model.fit(x_train, y_train, epochs=10, batch_size=batch_size)
loss, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))The major change here is the use of Conv2D layers. The relu activation function is already an argument of Conv2D. The relu function can be brought out as an Activation layer when the batch normalization layer is included in the model. Batch normalization is used in deep CNNs so that large learning rates can be used without causing instability during training.
If in the MLP model the number of units characterizes the Dense layers, the kernel characterizes the CNN operations. As shown in Figure 1.4.2, the kernel can be visualized as a rectangular patch or window that slides through the whole image from left to right, and top to bottom. This operation is called convolution. It transforms the input image into a feature maps, which is a representation of what the kernel has learned from the input image. The feature maps are then transformed into another feature maps in the succeeding layer and so on. The number of feature maps generated per Conv2D is controlled by the filters argument.
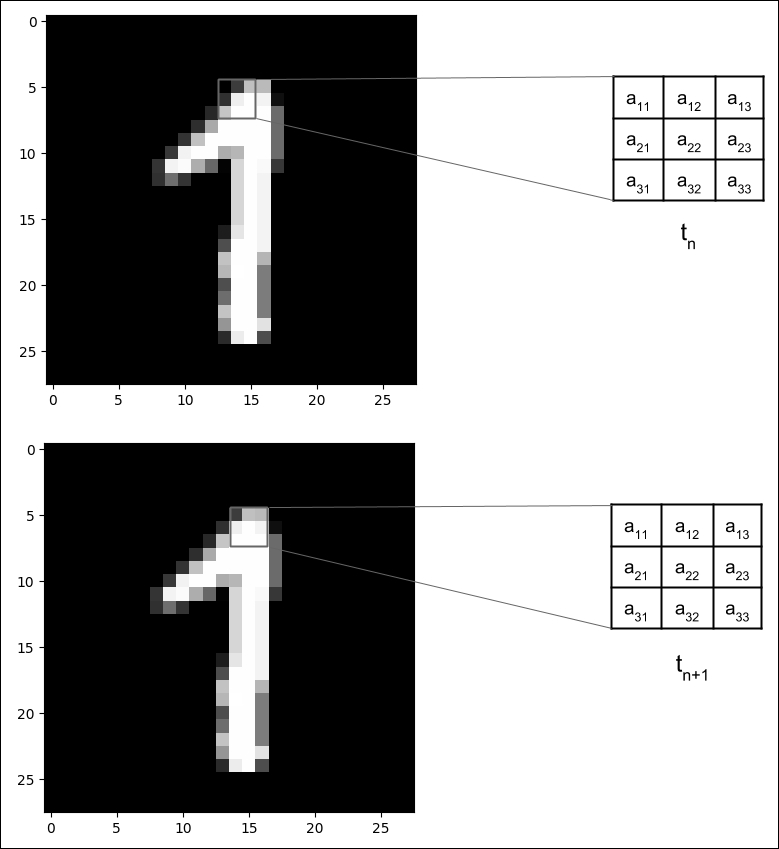
Figure 1.4.2: A 3 × 3 kernel is convolved with an MNIST digit image. The convolution is shown in steps tn and tn+1 where the kernel moved by a stride of 1 pixel to the right.
The computation involved in the convolution is shown in Figure 1.4.3. For simplicity, a 5 × 5 input image (or input feature map) where a 3 × 3 kernel is applied is illustrated. The resulting feature map is shown after the convolution. The value of one element of the feature map is shaded. You'll notice that the resulting feature map is smaller than the original input image, this is because the convolution is only performed on valid elements. The kernel cannot go beyond the borders of the image. If the dimensions of the input should be the same as the output feature maps, Conv2D will accept the option padding='same'. The input is padded with zeroes around its borders to keep the dimensions unchanged after the convolution:
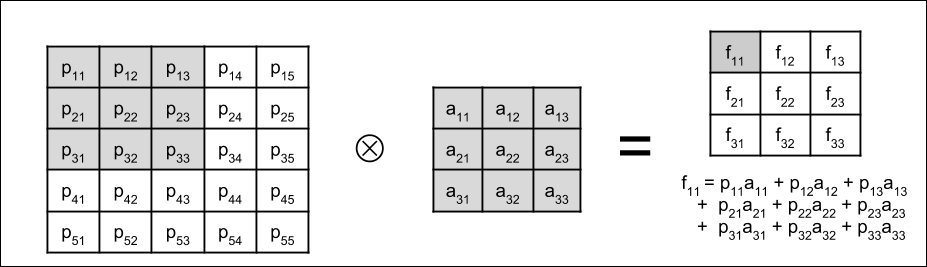
Figure 1.4.3: The convolution operation shows how one element of the feature map is computed
The last change is the addition of a MaxPooling2D layer with the argument pool_size=2. MaxPooling2D compresses each feature map. Every patch of size pool_size × pool_size is reduced to one pixel. The value is equal to the maximum pixel value within the patch. MaxPooling2D is shown in the following figure for two patches:
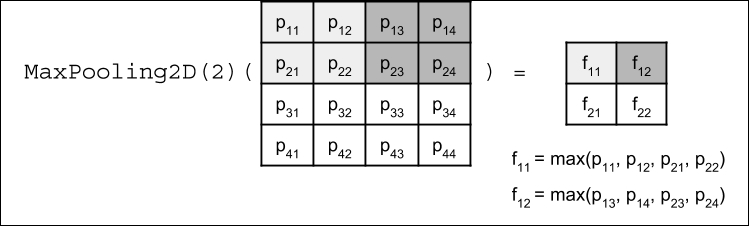
Figure 1.4.4: MaxPooling2D operation. For simplicity, the input feature map is 4 × 4 resulting in a 2 × 2 feature map.
The significance of MaxPooling2D is the reduction in feature maps size which translates to increased kernel coverage. For example, after MaxPooling2D(2), the 2 × 2 kernel is now approximately convolving with a 4 × 4 patch. The CNN has learned a new set of feature maps for a different coverage.
There are other means of pooling and compression. For example, to achieve a 50% size reduction as MaxPooling2D(2), AveragePooling2D(2) takes the average of a patch instead of finding the maximum. Strided convolution, Conv2D(strides=2,…) will skip every two pixels during convolution and will still have the same 50% size reduction effect. There are subtle differences in the effectiveness of each reduction technique.
In Conv2D and MaxPooling2D, both pool_size and kernel can be non-square. In these cases, both the row and column sizes must be indicated. For example, pool_size=(1, 2) and kernel=(3, 5).
The output of the last MaxPooling2D is a stack of feature maps. The role of Flatten is to convert the stack of feature maps into a vector format that is suitable for either Dropout or Dense layers, similar to the MLP model output layer.
As shown in Listing 1.4.2, the CNN model in Listing 1.4.1 requires a smaller number of parameters at 80,226 compared to 269,322 when MLP layers are used. The conv2d_1 layer has 640 parameters because each kernel has 3 × 3 = 9 parameters, and each of the 64 feature maps has one kernel and one bias parameter. The number of parameters for other convolution layers can be computed in a similar way. Figure 1.4.5 shows the graphical representation of the CNN MNIST digit classifier.
Table 1.4.1 shows that the maximum test accuracy of 99.4% which can be achieved for a 3–layer network with 64 feature maps per layer using the Adam optimizer with dropout=0.2. CNNs are more parameter efficient and have a higher accuracy than MLPs. Likewise, CNNs are also suitable for learning representations from sequential data, images, and videos.
Listing 1.4.2 shows a summary of a CNN MNIST digit classifier:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 26, 26, 64) 640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 13, 13, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 11, 11, 64) 36928 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 3, 3, 64) 36928 _________________________________________________________________ flatten_1 (Flatten) (None, 576) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 576) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 5770 _________________________________________________________________ activation_1 (Activation) (None, 10) 0 ================================================================= Total params: 80,266 Trainable params: 80,266 Non-trainable params: 0
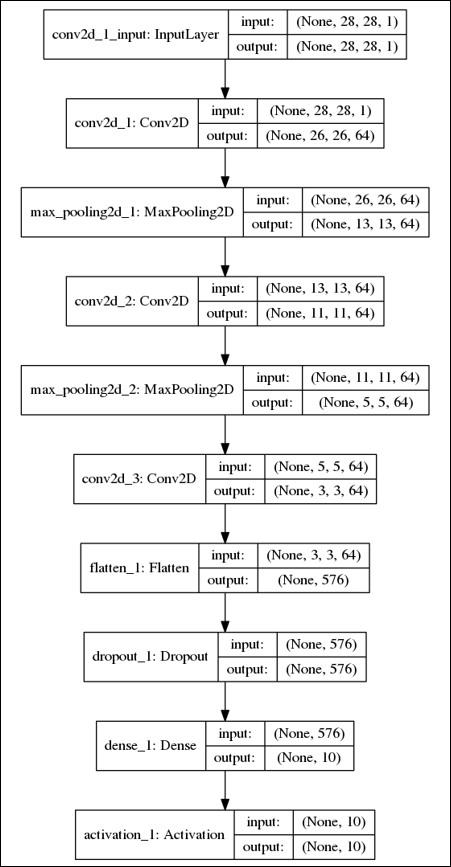
Figure 1.4.5: Graphical description of the CNN MNIST digit classifier
|
Layers |
Optimizer |
Regularizer |
Train Accuracy, % |
Test Accuracy, % |
|---|---|---|---|---|
|
64-64-64 |
SGD |
Dropout(0.2) |
97.76 |
98.50 |
|
64-64-64 |
RMSprop |
Dropout(0.2) |
99.11 |
99.00 |
|
64-64-64 |
Adam |
Dropout(0.2) |
99.75 |
99.40 |
|
64-64-64 |
Adam |
Dropout(0.4) |
99.64 |
99.30 |