

Now we are ready to understand SVMs. SVM is an algorithm that enables us to make use of it for both classification and regression. Given a set of examples, it builds a model to assign a group of observations into one category and others into a second category. It is a non-probabilistic linear classifier. Training data being linearly separable is the key here. All the observations or training data are a representation of vectors that are mapped into a space and SVM tries to classify them by using a margin that has to be as wide as possible:
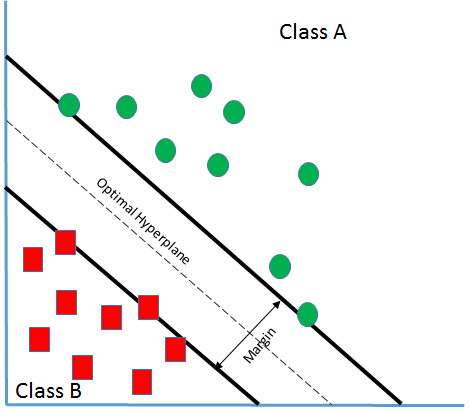
Let's say there are two classes A and B as in the preceding screenshot.
And from the preceding section, we have learned the following:
g(x) = w. x + b
Where:
- w: Weight vector that decides the orientation of the hyperplane
- b: Bias term that decides the position of the hyperplane in n-dimensional space by biasing it
The preceding equation is also called a linear discriminant function. If there is a vector x1 that lies on the positive side of the hyperplane...