

Let's now learn about machine learning, classification, and logistic regression.
Machine learning refers to the application of algorithms to make computers learn from data. The models that are learned by computers are used to make predictions and forecasts. Machine learning has been successfully applied in a variety of areas, such as natural language processing, self-driving vehicles, image and speech recognition, chatbots, and computer vision.
Machine learning algorithms are broadly categorized into three types:
- Supervised learning: In supervised learning, the machine learns the model from a training dataset that consists of features and labels. The supervised learning problems are generally of two types: regression and classification. Regression refers to predicting future values based on the model, while classification refers to predicting the categories of the input values.
- Unsupervised learning: In unsupervised learning, the machine learns the model from a training dataset that consists of features only. One of the most common types of unsupervised learning is known as clustering. Clustering refers to dividing the input data into multiple groups, thus producing clusters or segments.
- Reinforcement learning: In reinforcement learning, the agent starts with an initial model and then continuously learns the model based on the feedback from the environment. A reinforcement learning agent learns or updates the model by applying supervised or unsupervised learning techniques as part of the reinforcement learning algorithms.
These machine learning problems are abstracted to the following equation in one form or another:
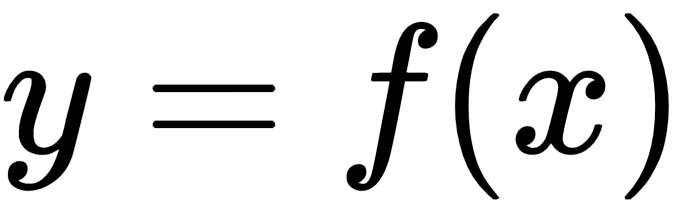
Here, y represents the target and x represents the feature. If x is a collection of features, it is also called a feature vector and denoted with X. The model is the function f that maps features to targets. Once the computer learns f, it can use the new values of x to predict the values of y.
The preceding simple equation can be rewritten in the context of linear models for machine learning as follows:
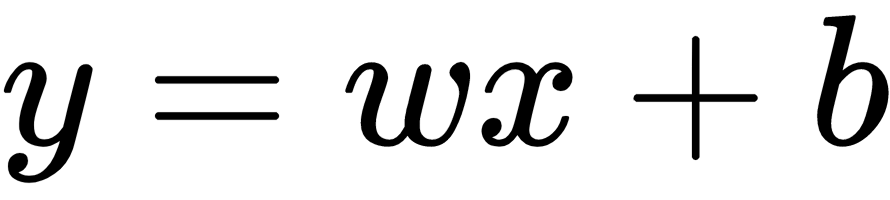
Here, w is known as the weight and b is known as the bias. Thus, the machine learning problem now can be stated as a problem of finding w and b from the current values of X so that the equation can now be used to predict the values of y.
Regression analysis or regression modeling refers to the methods and techniques used to estimate relationships among variables. The variables that are used as input for regression models are called independent variables, predictors, or features, and the output variables from regression models are called dependent variables or targets. Regression models are defined as follows:
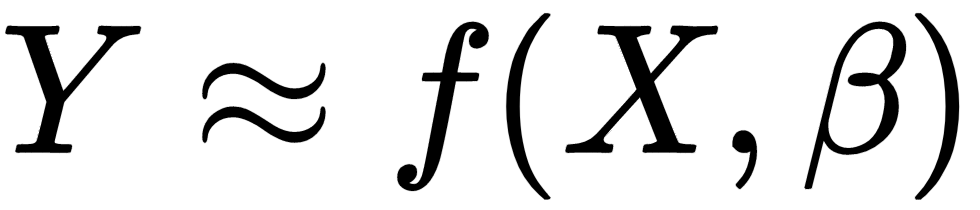
Where Y is the target variable, X is a vector of features, and β is a vector of parameters (w,b in the preceding equation).
Classification is one of the classical problems in machine learning. Data under consideration could belong to one class or another, for example, if the images provided are data, they could be pictures of cats or dogs. Thus, the classes, in this case, are cats and dogs. Classification means identifying the label or class of the objects under consideration. Classification falls under the umbrella of supervised machine learning. In classification problems, a training dataset is provided that has features or inputs and their corresponding outputs or labels. Using this training dataset, a model is trained; in other words, the parameters of the model are computed. The trained model is then used on new data to find its correct labels.
Classification problems can be of two types: binary class or multiclass. Binary class means that the data is to be classified into two distinct and discrete labels; for example, the patient has cancer or the patient does not have cancer, and the images are of cats or dogs and so on. Multiclass means that the data is to be classified among multiple classes, for example, an email classification problem will divide emails into social media emails, work-related emails, personal emails, family-related emails, spam emails, shopping offer emails, and so on. Another example would be of pictures of digits; each picture could be labeled between 0 and 9, depending on what digit the picture represents. In this chapter, we will look at examples of both kinds of classification.
The most popular method for classification is logistic regression. Logistic regression is a probabilistic and linear classifier. The probability that the vector of input features belongs to a specific class can be described mathematically by the following equation:
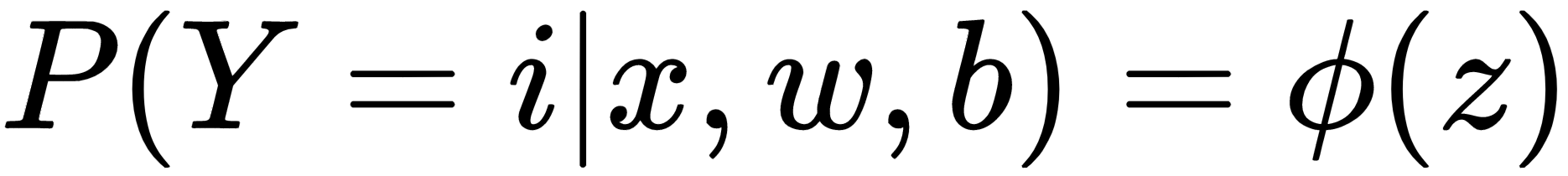
In the preceding equation, the following applies:
- Y represents the output
- i represents one of the classes
- x represents the inputs
- w represents the weights
- b represents the biases
- z represents the regression equation

- ϕ represents the smoothing function (or model, in our case)
The ϕ(z) function represents the probability that x belongs to class i when w and b are given. Thus, the model has to be trained to maximize the value of this probability.
For binary classification, the model function ϕ(z) is defined as the sigmoid function, which can be described as follows:
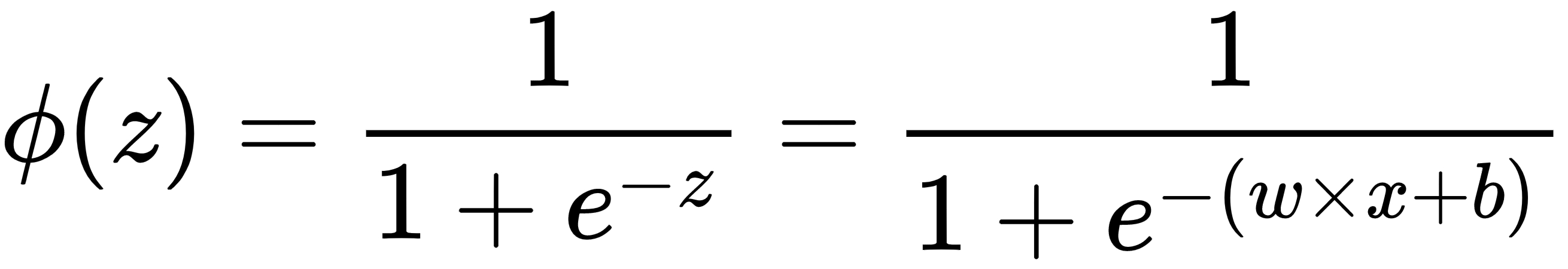
The sigmoid function transforms the y value to be between the range [0,1]. Thus, the value of y=ϕ(z) can be used to predict the class: if y > 0.5, then the object belongs to 1, otherwise the object belongs to 0.
The model training means to search for the parameters that minimize the loss function, which can either be the sum of squared errors or the sum of mean squared errors. For logistic regression, the likelihood is maximized as follows:
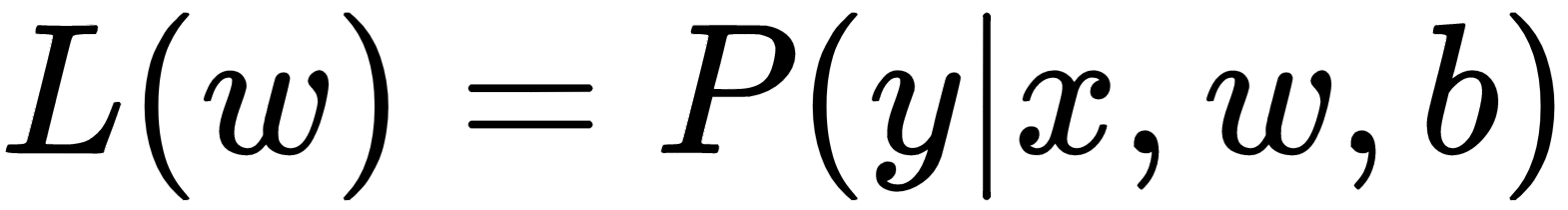
However, as it is easier to maximize the log-likelihood, we use the log-likelihood (l(w)) as the cost function. The loss function (J(w)) is written as -l(w), and can be minimized by using optimization algorithms such as gradient descent.
The loss function for binary logistic regression is written mathematically as follows:
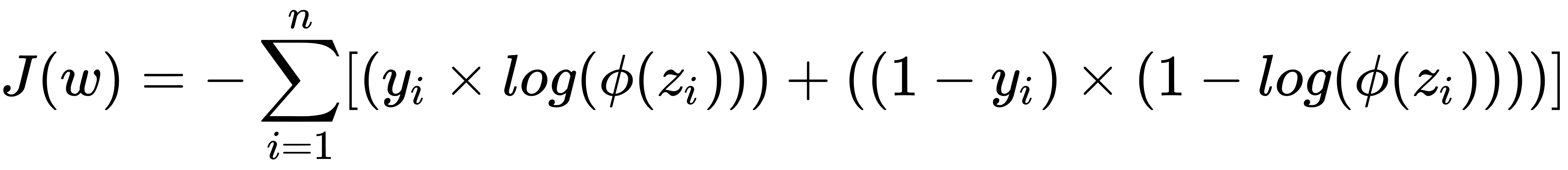
Here, ϕ(z) is the sigmoid function.
When more than two classes are involved, logistic regression is knownas multinomial logistic regression. In multinomial logistic regression, instead of sigmoid, use the softmax function, which can be described mathematically as follows:
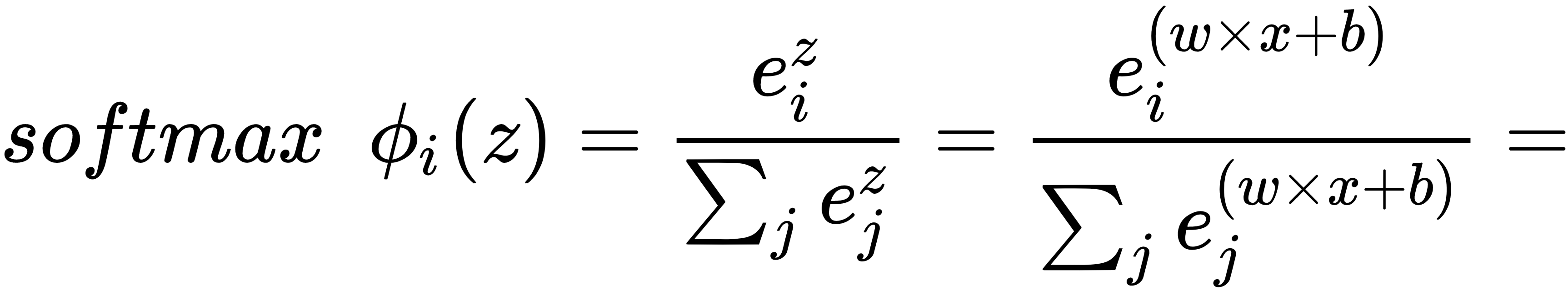
The softmax function produces the probabilities for each class so that the probabilities vector adds up to 1. At the time of inference, the class with the highest softmax value becomes the output or predicted class. The loss function, as we discussed earlier, is the negative log-likelihood function, -l(w), that can be minimized by the optimizers, such as gradient descent.
The loss function for multinomial logistic regression is written formally as follows:
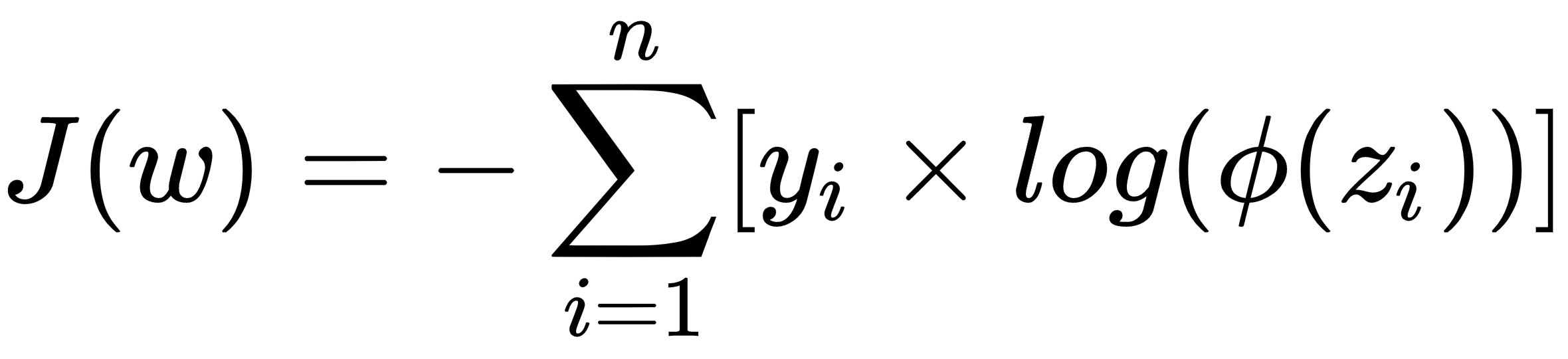
Here, ϕ(z) is the softmax function.
We will implement this loss function in the next section. In the following section, we will dig into our example for multiclass classification with logistic regression in TensorFlow.