

Let's consider a dataset of m-dimensional samples:
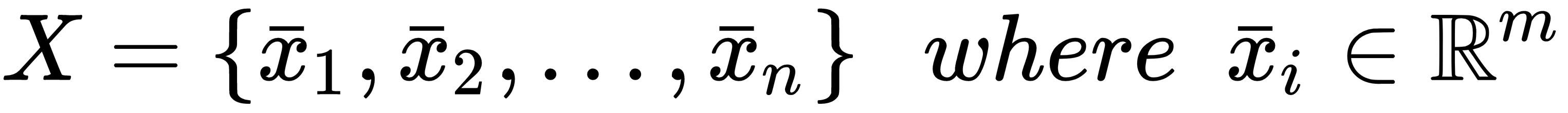
Let's assume that it's possible to find a criterion (not a unique) so that each sample can be associated with a specific group according to its peculiar features and the overall structure of the dataset:
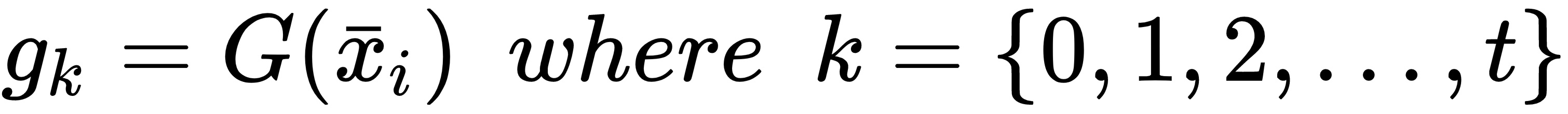
Conventionally, each group is called a cluster, and the process of finding the function, G, is called clustering. Right now, we are not imposing any restriction on the clusters; however, as our approach is unsupervised, there should be a similarity criterion to join some elements and separate other ones. Different clustering algorithms are based on alternative strategies to solve this problem, and can yield very different results.
In the following graph, there's an example of clustering based on four sets of bidimensional samples; the decision to assign a point to a cluster depends only...