

In this section, we will discuss the following problems:
- Mary and her temperature preference problems
- Map of Italy – choosing the value of k
- House ownership
In order to learn from the material from this chapter in the best way possible, please analyze these problems on your own first before looking at the Analysis section at the end of this chapter.
Problem 1: Imagine that you know that your friend Mary feels cold when it is -50°C, but she feels warm when it is 20°C. What would the 1-NN algorithm say about Mary? Would she feel warm or cold at temperatures of 22, 15, and -10? Do you think that the algorithm predicted Mary's body's perception of the temperature correctly? If not, please give your reasons and suggest why the algorithm did not give appropriate results and what would need to be improved for the algorithm to make a better classification.
Problem 2: Do you think that the 1-NN algorithm would yield better results than using the k-NN algorithm for k>1?
Problem 3: We collected more data and found out that Mary feels warmat 17°C, but cold at 18°C. Using our own common sense, Mary should feel warmer when the temperature is higher. Can you explain the possible cause of the discrepancies in the data? How could we improve the analysis of our data? Should we also collect some non-temperature data? Suppose that we have the only piece of temperature data available; do you think that the 1-NN algorithm would still yield better results with data like this? How should we choosekfor the k-NN algorithm to perform well?
Problem 4: We are given a partial map of Italy for the Map of Italy problem. However, suppose that the complete data is not available. Thus, we cannot calculate the error rate on all of the predicted points for different values of k. How should you choose the value of k for the k-NN algorithm, to complete the map of Italy with a view to maximizing its accuracy?
Problem 5: Using the data from the section concerned with the problem of house ownership, find the closest neighbor to Peter by using the Euclidean metric:
a) Without rescaling the data
b) By using the scaled data
Is the closest neighbor in:
a) The same as the neighbor in?
b) Which of the neighbors owns the house?
Problem 6: Suppose you would like to find books or documents in Gutenberg's corpus (www.gutenberg.org) that are similar to a selected book from the corpus (for example, the Bible) by using a certain metric and the 1-NN algorithm. How would you design a metric measuring the similarity distance between the two books?
Problem 1: 8°C is closer to 20°C than to -50°C. So, the algorithm would classify Mary as feeling warm at -8°C. But this is not likely to be true if we use our common sense and knowledge. In more complex examples, we may be deluded by the results of the analysis and make false conclusions due to our lack of expertise. But remember that data science makes use of substantive and expert knowledge, not only data analysis. In order to draw sound conclusions, we should have a good understanding of the problem and our data.
The algorithm further says that at 22°C, Mary should feel warm, and there is no doubt in that, as 22°C is higher than 20°C, and a human being feels warmer with a higher temperature; again, a trivial use of our knowledge. For 15°C, the algorithm would deem Mary to feel warm, but if we use our common sense, we may not be that certain of this statement.
To be able to use our algorithm to yield better results, we should collect more data. For example, if we find out that Mary feels cold at 14°C, then we have a data instance that is very close to 15° and, thus, we can guess with a higher degree of certainty that Mary would feel cold at a temperature of 15°.
Problem 2: The data we are dealing with is just one-dimensional and is also partitioned into two parts, cold and warm, with the following property: the higher the temperature, the warmer a person feels. Also, even if we know how Mary feels at the temperatures -40, -39, …, 39, and 40, we still have a very limited amount of data instances – just one for around every degree Celsius. For these reasons, it is best to just look at one closest neighbor.
Problem 3: Discrepancies in the data can be caused by inaccuracies in the tests carried out. This could be mitigated by performing more experiments.
Apart from inaccuracy, there could be other factors that influence how Mary feels: for example, the wind speed, humidity, sunshine, how warmly Mary is dressed (whether she has a coat on with jeans, or just shorts with a sleeveless top, or even a swimming suit), and whether she is wet or dry. We could add these additional dimensions (wind speed and how she is dressed) into the vectors of our data points. This would provide more, and better quality, data for the algorithm and, consequently, better results could be expected.
If we have only temperature data, but more of it (for example, 10 instances of classification for every degree Celsius), then we could increase the k value and look at more neighbors to determine the temperature more accurately. But this purely relies on the availability of the data. We could adapt the algorithm to yield the classification based on all the neighbors within a certain distance, d, rather than classifying based on the k-closest neighbors. This would make the algorithm work well in both cases when we have a lot of data within a close distance, and when we have just one data instance close to the instance that we want to classify.
Problem 4: For this purpose, you can use cross-validation (consult the Cross-validation section in Appendix A – Statistics) to determine the value of k with the highest accuracy. You could separate the available data from the partial map of Italy into learning and test data, for example, 80% of the classified pixels on the map would be given to a k-NN algorithm to complete the map. Then, the remaining 20% of the classified pixels from the partial map would be used to calculate the percentage of pixels with the correct classification according to the k-NN algorithm.
Problem 5:
a) Without data rescaling, Peter's closest neighbor has an annual income of USD 78,000 and is aged 25. This neighbor does not own a house.
b) After data rescaling, Peter's closest neighbor has an annual income of USD 60,000 and is aged 40. This neighbor owns a house.
Problem 6: To design a metric that accurately measures the similarity distance between the two documents, we need to select important words that will form the dimensions of the frequency vectors for the documents. Words that do not determine the semantic meaning of documents tend to have an approximately similar frequency count across all documents. Thus, instead, we could produce a list with the relative word frequency counts for a document. For example, we could use the following definition:
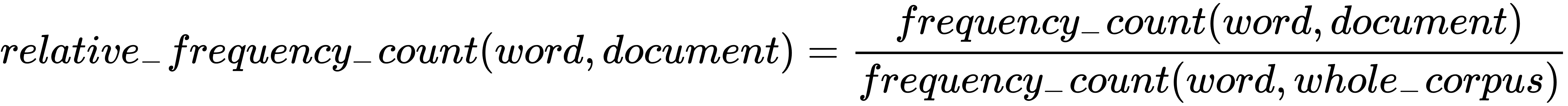
Then, the document could be represented by an N-dimensional vector consisting of the word frequencies for N words with the highest relative frequency count. Such a vector will tend to consist of more important words than a vector of N words with the highest frequency count.