-
Book Overview & Buying

-
Table Of Contents

Learn Helm
By :
Learn Helm
By:
Overview of this book
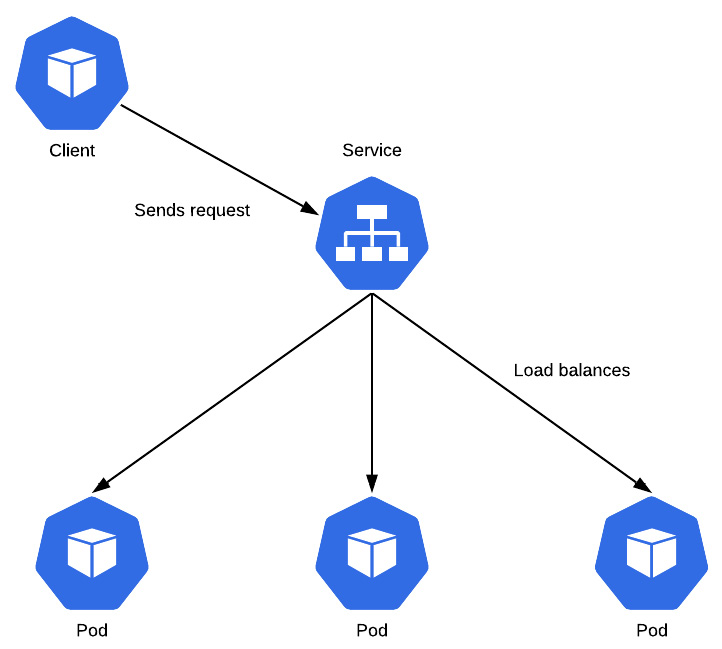
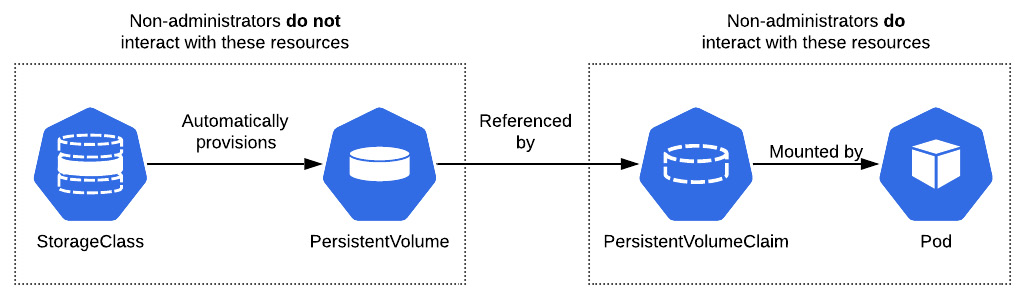
Containerization is currently known to be one of the best ways to implement DevOps. While Docker introduced containers and changed the DevOps era, Google developed an extensive container orchestration system, Kubernetes, which is now considered the frontrunner in container orchestration. With the help of this book, you’ll explore the efficiency of managing applications running on Kubernetes using Helm.
Starting with a short introduction to Helm and how it can benefit the entire container environment, you’ll then delve into the architectural aspects, in addition to learning about Helm charts and its use cases. You’ll understand how to write Helm charts in order to automate application deployment on Kubernetes. Focused on providing enterprise-ready patterns relating to Helm and automation, the book covers best practices for application development, delivery, and lifecycle management with Helm.
By the end of this Kubernetes book, you will have learned how to leverage Helm to develop an enterprise pattern for application delivery.
Table of Contents (15 chapters)
Preface

Section 1: Introduction and Setup
 Free Chapter
Free Chapter
Chapter 1: Understanding Kubernetes and Helm
Chapter 2: Preparing a Kubernetes and Helm Environment
Chapter 3: Installing your First Helm Chart
Section 2: Helm Chart Development
Chapter 4: Understanding Helm Charts
Chapter 5: Building Your First Helm Chart
Chapter 6: Testing Helm Charts
Section 3: Adanced Deployment Patterns
Chapter 7: Automating Helm Processes Using CI/CD and GitOps
Chapter 8: Using Helm with the Operator Framework
Chapter 9: Helm Security Considerations
ASSESSMENTS
Other Books You May Enjoy