

Bridges in Linux are a key building block for network connectivity. Docker uses them extensively in many of its own network drivers that are included with docker-engine. Bridges have been around for a long time and are, in most cases, very similar to a physical network switch. Bridges in Linux can act like layer 2 or layer 3 bridges.
Note
Layer 2 versus layer 3
The nomenclature refers to different layers of the OSI network model. Layer 2 represents the data link layer and is associated with switching frames between hosts. Layer 3 represents the network layer and is associated with routing packets across the network. The major difference between the two is switching versus routing. A layer 2 switch is capable of sending frames between hosts on the same network but is not capable of routing them based on IP information. If you wish to route between two hosts on different networks or subnets, you'll need a layer 3 capable device that can route between the two subnets. Another way to look at this is that layer 2 switches can only deal with MAC addresses and layer 3 devices can deal with IP addresses.
By default, Linux bridges are layer 2 constructs. In this manner, they are often referred to as protocol independent. That is, any number of higher level (layer 3) protocols can run on the same bridge implementation. However, you can also assign an IP address to a bridge that turns it into a layer 3 capable networking construct. In this recipe, we'll show you how to create, manage, and inspect Linux bridges by walking through a couple of examples.
In order to view and manipulate networking settings, you'll want to ensure that you have the iproute2 toolset installed. If not present on the system, it can be installed by using the following command:
sudo apt-get install iproute2
In order to make network changes to the host, you'll also need root-level access. This recipe will continue the lab topology from the previous recipe. All of the prerequisites mentioned earlier still apply.
To demonstrate how bridges work, let's consider making a slight change to the lab topology we've been working with:
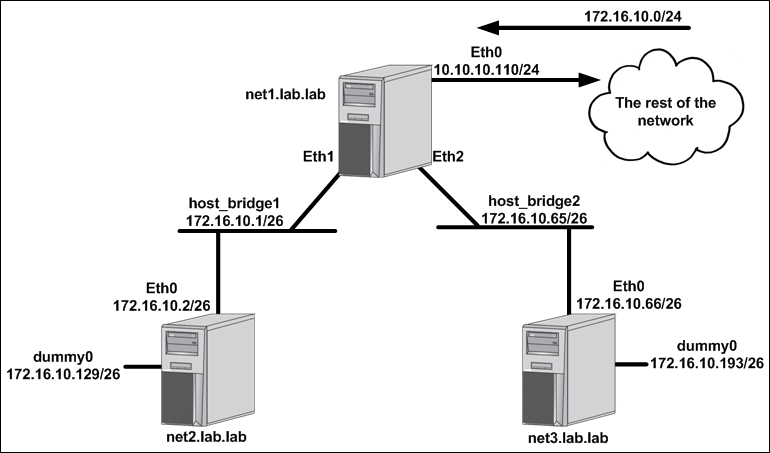
Rather than having the servers directly connect to each other via physical interfaces, we'll instead leverage bridges on the host net1 for connectivity to downstream hosts. Previously, we relied on a one-to-one mapping for connections between net1 and any other hosts. This meant that we'd need a unique subnet and IP address configuration for each physical interface. While that's certainly doable, it's not very practical. Leveraging bridge interfaces rather than standard interfaces affords us some flexibility we didn't have in the earlier configurations. We can assign a single IP address to a bridge interface and then plumb many physical connections into the same bridge. For example, a net4 host could be added to the topology and its interface on net1 could simply be added to host_bridge2. That would allow it to use the same gateway (172.16.10.65) as net3. So while the physical cabling requirement for adding hosts won't change, this does prevent us from having to define one-to-one IP address mappings for each host.
Note
From the perspective of the hosts net2 and net3, nothing will change when we reconfigure to use bridges.
Since we're changing how we define the net1 host's eth1 and eth2 interface, we'll start by flushing their configuration:
user@net1:~$ sudo ip address flush dev eth1 user@net1:~$ sudo ip address flush dev eth2
Flushing the interface simply clears any IP-related configuration off of the interface. The next thing we have to do is to create the bridges themselves. The syntax we use is much like we saw in the previous recipe when we created the dummy interfaces. We use the ip link add command and specify a type of bridge:
user@net1:~$ sudo ip link add host_bridge1 type bridge user@net1:~$ sudo ip link add host_bridge2 type bridge
After creating the bridges, we can verify that they exist by examining the available interfaces with the ip link show <interface> command:
user@net1:~$ ip link show host_bridge1 5: host_bridge1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default link/ether f6:f1:57:72:28:a7 brd ff:ff:ff:ff:ff:ff user@net1:~$ ip link show host_bridge2 6: host_bridge2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default link/ether be:5e:0b:ea:4c:52 brd ff:ff:ff:ff:ff:ff user@net1:~$
Next, we want to make them layer 3 aware, so we assign an IP address to the bridge interface. This is very similar to how we assigned IP addressing to physical interfaces in previous recipes:
user@net1:~$ sudo ip address add 172.16.10.1/26 dev host_bridge1 user@net1:~$ sudo ip address add 172.16.10.65/26 dev host_bridge2
We can verify that the IP addresses were assigned by using the ip addr show dev <interface> command:
user@net1:~$ ip addr show dev host_bridge1 5: host_bridge1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default link/ether f6:f1:57:72:28:a7 brd ff:ff:ff:ff:ff:ff inet 172.16.10.1/26 scope global host_bridge1 valid_lft forever preferred_lft forever user@net1:~$ ip addr show dev host_bridge2 6: host_bridge2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default link/ether be:5e:0b:ea:4c:52 brd ff:ff:ff:ff:ff:ff inet 172.16.10.65/26 scope global host_bridge2 valid_lft forever preferred_lft forever user@net1:~$
The next step is to bind the physical interfaces associated with each downstream host to the correct bridge. In our case, we want the host net2, which is connected to net1's eth1 interface to be part of the bridge host_bridge1. Similarly, we want the host net3, which is connected to net1's eth2 interface, to be part of the bridge host_bridge2. Using the ip link set subcommand, we can define the bridges to be the masters of the physical interfaces:
user@net1:~$ sudo ip link set dev eth1 master host_bridge1 user@net1:~$ sudo ip link set dev eth2 master host_bridge2
We can verify that the interfaces were successfully bound to the bridge by using the bridge link show command.
Note
The bridge command is part of the iproute2 package and is used to validate bridge configuration.
user@net1:~$ bridge link show 3: eth1 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master host_bridge1 state forwarding priority 32 cost 4 4: eth2 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master host_bridge2 state forwarding priority 32 cost 4 user@net1:~$
Finally, we need to turn up the bridge interfaces as they are, by default, created in a down state:
user@net1:~$ sudo ip link set host_bridge1 up user@net1:~$ sudo ip link set host_bridge2 up
Once again, we can now check the link status of the bridges to verify that they came up successfully:
user@net1:~$ ip link show host_bridge1 5: host_bridge1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 00:0c:29:2d:dd:83 brd ff:ff:ff:ff:ff:ff user@net1:~$ ip link show host_bridge2 6: host_bridge2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 00:0c:29:2d:dd:8d brd ff:ff:ff:ff:ff:ff user@net1:~$
At this point, you should once again be able to reach the hosts net2 and net3. However, the dummy interfaces are now unreachable. This is because the routes for the dummy interfaces were automatically withdrawn after we flushed interface eth1 and eth2. Removing the IP addresses from those interfaces made the next hops used to reach the dummy interfaces unreachable. It is common for a device to withdraw a route from its routing table when the next hop becomes unreachable. We can add them again rather easily:
user@net1:~$ sudo ip route add 172.16.10.128/26 via 172.16.10.2 user@net1:~$ sudo ip route add 172.16.10.192/26 via 172.16.10.66
Now that everything is working again, we can perform some extra steps to validate the configuration. Linux bridges, much like real layer 2 switches, can also keep track of the MAC addresses they receive. We can view the MAC addresses the system is aware of by using the bridge fdb show command:
user@net1:~$ bridge fdb show …<Additional output removed for brevity>… 00:0c:29:59:ca:ca dev eth1 00:0c:29:17:f4:03 dev eth2 user@net1:~$
The two MAC addresses we see in the preceding output reference the directly connected interfaces that net1 talks to in order to get to hosts net2 and net3 as well as the subnets defined on their associated dummy0 interfaces. We can verify this by looking at the hosts ARP table:
user@net1:~$ arp -a ? (10.10.10.1) at 00:21:d7:c5:f2:46 [ether] on eth0 ? (172.16.10.2) at 00:0c:29:59:ca:ca [ether] on host_bridge1 ? (172.16.10.66) at 00:0c:29:17:f4:03 [ether] on host_bridge2 user@net1:~$
Note
There aren't many scenarios where the old tool is better, but in the case of the bridge command-line tool, some might argue that the older brctl tool has some advantages. For one, the output is a little easier to read. In the case of learned MAC addresses, it will give you a better view into the mappings with the brctl showmacs <bridge name> command. If you want to use the older tool, you can install the bridge-utils package.
Removing interfaces from bridges can be accomplished through the ip link set subcommand. For instance, if we wanted to remove eth1 from the bridge host_bridge1 we would run this command:
sudo ip link set dev eth1 nomaster
This removes the master slave binding between eth1 and the bridge host_bridge1. Interfaces can also be reassigned to new bridges (masters) without removing them from the bridge they are currently associated with. If we wanted to delete the bridge entirely, we could do so with this command:
sudo ip link delete dev host_bridge2
It should be noted that you do not need to remove all of the interfaces from the bridge before you delete it. Deleting the bridge will automatically remove all master bindings.