

A parallel system contains more than one processor having direct memory access to the shared memory that can form a common address space. Usually, a parallel system is of a Uniform Memory Access (UMA) architecture. In UMA architecture, the access latency (processing time) for accessing any particular location of a memory from a particular processor is the same. Moreover, the processors are also configured to be in a close proximity and are connected in an interconnection network. Conventionally, the interprocess processor communication between the processors is happening through either read or write operations across a shared memory, even though the usage of the message-passing capability is also possible (with emulation on the shared memory). Moreover, the hardware and software are tightly coupled, and usually, the processors in such network are installed to run on the same operating system. In general, the processors are homogeneous and are installed within the same container of the shared memory. A multistage switch/bus containing a regular and symmetric design is used for greater efficiency.
The following diagram represents a UMA parallel system with multiple processors connecting to multiple memory units through network connection.

A multicomputer parallel system is another type of parallel system containing multiple processors configured without having a direct accessibility to the shared memory. Moreover, a common address space may or may not be expected to be formed by the memory of the multiple processors. Hence, computers belonging to this category are not expected to contain a common clock in practice. The processors are configured in a close distance, and they are also tightly coupled in general with homogeneous software and hardware. Such computers are also connected within an interconnected network. The processors can establish a communication with either of the common address space or message passing options. This is represented in the diagram below.

A multicomputer system in a Non-Uniform Memory Access (NUMA) architecture is usually configured with a common address space. In such NUMA architecture, accessing different memory locations in a shared memory across different processors shows different latency times.
Array processor exchanges information by passing as messages. Array processors have a very small market owing to the fact that they can perform closely synchronized data processing, and the data is exchanged in a locked event for applications such as digital signal processing and image processing. Such applications can also involve large iterations on the data as well.
Compared to the UMA and array processors architecture, NUMA as well as message-passing multicomputer systems are less preferred if the shared data access and communication much accepted. The primary benefit of having parallel systems is to derive a better throughput through sharing the computational tasks between multiple processors. The tasks that can be partitioned into multiple subtasks easily and need little communication for bringing synchronization in execution are the most efficient tasks to execute on parallel systems. The subtasks can be executed as a large vector or an array through matrix computations, which are common in scientific applications. Though parallel computing was much appreciated through research and was beneficial on legacy architectures, they are observed no more efficient/economic in recent times due to following reasons:
- They need special configuration for compilers
- The market for such applications that can attain efficiency through parallel processing is very small
- The evolution of more powerful and efficient computers at lower costs made it less likely that organizations would choose parallel systems.
Amdahl's law is frequently considered in parallel computing to forecast the improvement in process speedup when increasing the use of multiple system processors. Amdahl's Law is named after the famous computer scientist Gene Amdahl; it was submitted at the American Federation of Information Processing Societies (AFIPS) during the Spring Joint Computer Conference in the year 1967.
The standard formula for Amdahl's Law is as follows:
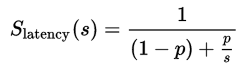
where:
- Slatency is the calculated improvement of the latency (execution) of the complete task.
- s is the improvement in execution of the part of the task that benefits from the improved system resources.
- p is the proportion of the execution time that the part benefiting from improved resources actually occupies.
Let's consider an example of a single task that can be further partitioned into four subtasks: each of their execution time percentages are p1 = 0.11, p2 = 0.18, p3 = 0.23, and p4 = 0.48, respectively. Then, it is observed that the first subtask is improved in speed, so s1 = 1. The second subtask is observed to be improved in speed by five times, so s2 = 5. The third subtask is observed to be improved in speed by 20 times, so s3 = 20. Finally, the fourth subtask is improved in speed by 1.6 times, so s4 = 1.6.
By using Amdahl's law, the overall speedup is follows:
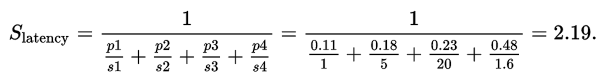
Notice how the 20 times and 5 times speedup on the second and third parts, respectively, don't have much effect on the overall speedup when the fourth part (48% of the execution time) is sped up only 1.6 times.
The following formula demonstrates that the theoretical speedup of the entire program execution improves with the increase of the number/capacity of resources in the system and that, regardless with the magnitude of the improvement, the calculated improvement of the entire program is always expected to be limited by that particular task that cannot benefit from the resource improvement.
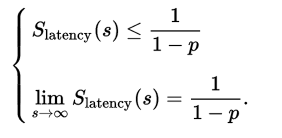
Consider if a program is expected to need about 20 hours to complete the processing with the help of a single processor. A specific sub task of the entire program that is expected to consume an hour to execute cannot be executed in parallel, while the remaining program of about 19 hours processing (p = 0.95) of the total execution time can be executed in parallel. In such scenarios, regardless of how many additional processors are dedicated to be executed in parallel of such program, the execution time of the program cannot be reduced to anytime less than that minimum 1 hour. Obviously, the expected calculated improvement of the execution speed is limited to, at most, 20 times (calculated as 1/(1 − p) = 20). Hence, parallel computing is applicable only for those processors that have more scope for having the capability of splitting them into subtasks/parallel programs as observed in the diagram below.

However, Amdahl's law is applicable only to scenarios where the program is of a fixed size. In general, on larger problems (larger datasets), more computing resources tend to get used if they are available, and the overall processing time in the parallel part usually improves much faster than the by default serial parts.