These days, with the use of serverless technology, we aim to deploy smaller pieces of code much faster. We're still developing within a domain, but we no longer have to worry about the details of our runtime. We're not focusing on building infrastructure, platform services, or application servers – we can use the runtime to write code that maps directly to business value.
A key reason for a serverless development model is that it lowers the Time to Value. The time it takes to define a problem, build the business logic, and deliver the value to a user has dramatically reduced. A factor that contributes to this is that developer productivity is not constrained by other dependencies, such as provisioning infrastructure. Furthermore, each developer can produce a higher value output because the code they are writing actually does useful things. Developers can ship releases sooner—a few days from dev to production—meaning the overall development costs are less as well.
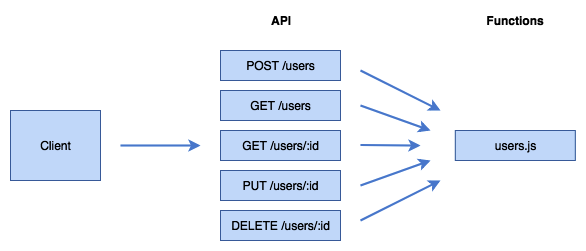
Microservices can become more modular again with the introduction of nanoservices. While a microservice may accept multiple commands, for example, get user, create user, modify user attribute—a nanoservice will do exactly one thing, for example, get user. The lines between micro and nano are often blurred, and it raises a challenge as to how small or big we actually make that nanoservice.
A nanoservice still works within a particular domain to solve a problem, but the scope of functionality is narrower. Many nanoservices can make up one microservice, with each nanoservice knowing where to find the source data and how to structure the data for a meaningful response. Each nanoservice also manages its own error handling. For example, when paired with a RESTful API, this would mean being able to return a 5xx HTTP response. A 5xx response is an HTTP status code.
Nanoservice with one function for each API operation
Nanoservices can be helpful because they allow us to go deeper into the parts of the application that we are getting the most use out of. Reporting for cost control can be fine-grained and can also help a Product Owner prioritize the optimization of a particular function.
One key principle of a nanoservice is that it must be more useful that the overhead it incurs.
While the code within a function can be more simple, having many more functions increases the complexity of deployment, versioning, and maintaining a registry of functionality. As we'll find out later in this book, there is an application framework called the serverless framework that is very useful for managing these challenges. Something else that was released recently is the AWS Serverless Application Repository, which is a registry of useful domain logic (nanoservices) that developers can use as building blocks in their own functional applications.
In terms of communication overheads between nanoservices, it's advisable to minimize the number of synchronous callouts that a nanoservice does; otherwise, the service may be waiting a while for all the pieces of information it needs before the service can assemble a response.
In that case, a fire-and-forget invocation style where functions are called asynchronously may be more suitable or rethinking where the source data resides.
A nanoservice should be reusable but doesn't necessarily have to be usable as a complete service on its own. What it should follow is the Unix principles of small, composable applications that can be used as building blocks for larger applications. Think about the sed or grep Unix commands. These smaller utilities are useful by themselves, but can also be used to make up larger applications. An example of this is that you may have a microservice that is responsible for managing everything to do with room bookings in a hotel. A nanoservice may break this into specific discrete tasks to do with bookings, such as creating a new booking, finding a specific attribute, or performing a specific system integration. Each nanoservice can be used to make up the room booking workflow, and can also be used by other applications where useful.
Developing applications that are made up of nanoservices makes it easier to make changes to functions with a smaller potential impact. With serverless technologies such as AWS Lambda, it's also possible to deploy these changes without an outage to the service, provided the new change is still compatible with its consumers.
As we mentioned earlier, choosing to go to the granularity of a nanoservice comes with certain challenges. In a dynamic team with an ever-increasing number of nanoservices, thought has to be put into how to approach the following topics:
- Service sprawl, where we have lots of nanoservices performing the same or similar functions.
- Inter-service dependencies in terms of how we maintain which nanoservices have relationships with other services and data sources.
- Too big or too small, that is, when do we make the distinction about when the overhead becomes too burdensome?
- What is the usage pattern? Am I doing complex computational tasks, long-running tasks, or do I rely on a large amount of memory? Such patterns may be better suited for a microservice hosted in a container.
Some say that functions in the serverless world are the smallest level of granularity that we should abstract to. Next, we'll put our thinking hats on and see what we think may be coming up in our next architecture evolution.