

A good network design is an important step to bringing a Ceph cluster online. If your networking is handled by another team, make sure that they are included at all stages of the design as often an existing network will not be designed to handle Ceph's requirements, leading to both poor Ceph performance as well as impacting existing systems.
It's recommended that each Ceph node be connected via redundant links to two separate switches so that in the event of a switch failure, the Ceph node is still accessible. Stacking switches should be avoided if possible, as they can introduce single points of failure and in some cases are both required to be offline to carry out firmware upgrades.
If your Ceph cluster will be contained purely in one set of switches, feel free to skip this next section.
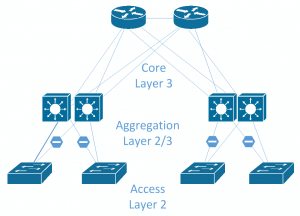
Traditional networks were mainly designed around a North-South access path, where clients at the North, access data through the network to servers at the South. If a server connected to an access switch needed to talk to another server connected to another access switch, the traffic would be routed through the core switch. Due to this access pattern, the access and aggregation layers that feed into the core layer were not designed to handle a lot of intraserver traffic, which is fine for the environment they were designed to support. Server-to-server traffic is named East-West traffic and is becoming more prevalent in the modern data center as applications become less isolated and require data from several other servers.
Ceph generates a lot of East-West traffic, not only from internal cluster replication traffic, but also from other servers consuming Ceph storage. In large environments, the traditional core, aggregation, and access layer design may struggle to cope as large amounts of traffic will be expected to be routed through the core switch. Faster switches can be obtained, and faster or more uplinks can be added; however, the underlying problem is that you are trying to run a scale-out storage system on a scale-up network design. Following image shows a typical network design with Core, Aggregation and Access layers. Typically only a single link from the access to the aggregation layer will be active.
A design that is becoming very popular in data centers is leaf-spine design. This approach completely gets rid of the traditional model and instead replaces it with two layers of switches: the spine layer and the leaf layer. The core concept is that each leaf switch connects to every spine switch so that any leaf switch is only one hop anyway from any other leaf switch. This provides consistent hop latency and bandwidth. Following is an example of a leaf spine toplogy. Depending on failure domains you may wish to have single or multiple leaf switches per rack for redundancy.

The leaf layer is where the servers connect into and is typically made up of a large number of 10G ports and a handful of 40G or faster uplink ports to connect into the spine layer.
The spine layer won't normally connect directly into servers, unless there are certain special requirements and will just serve as an aggregation point for all the leaf switches. The spine layer will often have higher port speeds to reduce any possible contention of the traffic coming out of the leaf switches.
Leaf spine networks are typically moving away from pure layer 2 topology, where layer 2 domain is terminated on the leaf switches and layer 3 routing is done between the leaf and spine layer. This is advised to be done using dynamic routing protocols, such as Border Gateway Protocol (BGP) or Open Shortest Path First (OSPF), to establish the routes across the fabric. This brings numerous advantages over large layer 2 networks. Spanning tree, which is typically used in layer 2 networks to stop switching loops, works by blocking an uplink, when using 40G uplinks; this is a lot of bandwidth to lose. When using dynamic routing protocols with a layer 3 design, Equal-cost multi-path (ECMP) routing can be used to fairly distribute data over all uplinks to maximize the available bandwidth. In the example of a leaf switch connected to two spine switches via a 40G uplink, there would be 80G of bandwidth available to any other leaf switch in the topology, no matter where it resides.
Some network designs take this even further and push the layer 3 boundary down to the servers by actually running these routing protocols on servers as well so that ECMP can be used to simplify the use of both NICs on the server in an active/active fashion. This is named Routing on the Host.