A static inventory is great, and enough for many situations. But there are times when a statically written set of hosts is just too unwieldy to manage. Consider situations where inventory data already exists in a different system, such as LDAP, a cloud computing provider, or an in-house configuration management database (CMDB) (inventory, asset tracking, and data warehousing) system. It would be a waste of time and energy to duplicate that data and, in the modern world of on-demand infrastructure, that data would quickly grow stale or disastrously incorrect.
Another example of when a dynamic inventory source might be desired is when your site grows beyond a single set of playbooks. Multiple playbook repositories can fall into the trap of holding multiple copies of the same inventory data, or complicated processes have to be created to reference a single copy of the data. An external inventory can easily be leveraged to access the common inventory data stored outside of the playbook repository to simplify the setup. Thankfully, Ansible is not limited to static inventory files.
A dynamic inventory source (or plugin) is an executable that Ansible will call at runtime to discover real-time inventory data. This executable may reach out into external data sources and return data, or it can just parse local data that already exists but may not be in the Ansible inventory ini format. While it is possible, and easy, to develop your own dynamic inventory source, which we will cover in a later chapter, Ansible provides a number of example inventory plugins, including, but not limited to, the following:
- OpenStack Nova
- Rackspace Public Cloud
- DigitalOcean
- Linode
- Amazon EC2
- Google Compute Engine
- Microsoft Azure
- Docker
- Vagrant
Many of these plugins require some level of configuration, such as user credentials for EC2 or authentication endpoint for OpenStack Nova. Since it is not possible to configure additional arguments for Ansible to pass along to the inventory script, the configuration for the script must either be managed via an ini config file read from a known location, or environment variables read from the shell environment used to execute ansible or ansible-playbook. Note also that sometimes, external libraries are required for these inventory scripts to function.
When ansible or ansible-playbook is directed at an executable file for an inventory source, Ansible will execute that script with a single argument, --list. This is so that Ansible can get a listing of the entire inventory in order to build up its internal objects to represent the data. Once that data is built up, Ansible will then execute the script with a different argument for every host in the data to discover variable data. The argument used in this execution is --host <hostname>, which will return any variable data specific to that host.
The inventory scripts are too numerous to go through each in detail in this book. However, to demonstrate the process, we will work through the use of the EC2 dynamic inventory. The dynamic inventory scripts officially included with Ansible can be found on Github:
https://github.com/ansible/ansible/tree/devel/contrib/inventory
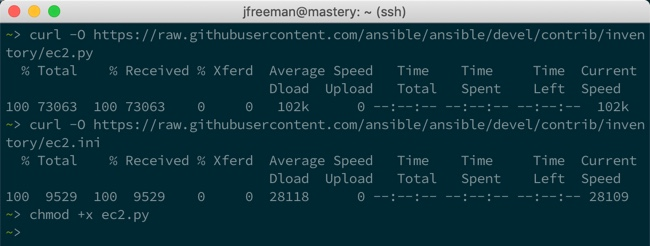
On browsing this directory system, we can see there is an ec2.py and associated example configuration file, ec2.ini. Download these onto your system and make the Python file executable:
If we take a look at the comments at the top of ec2.py, we can see it tells us that we need the Boto library installed. Installing this will depend on your operating system and Python environment, but on CentOS 7 (and other EL7 variants), it could be done with the following:
Now, take a look at the ec2.ini file, and edit it as appropriate. You can see that your AWS credentials could go into this file, but it is not recommended for security reasons. For this example, we will simply specify them using environment variables, and then run our dynamic inventory script with the --list parameter, as discussed in the previous screenshot. Doing so yields the following:
Voila! We have a listing of our current AWS inventory, along with a glimpse into the host variables for the discovered hosts. Note that, of course, the full output is far more complete than this.
With the AWS inventory in place, you could use this right away to run a single task or entire playbook against this dynamic inventory. For example, to use the ping module to check Ansible connectivity to all hosts in the inventory, you could run the following command:
ansible -i ec2.py all -m ping
This, of course, is just one example. However, if you follow this process for other dynamic inventory providers, you should get them working with ease.
In Chapter 9, Extending Ansible, we will develop our own custom inventory plugin to demonstrate how they operate.