

Exploring the transition from monolithic to microservices
I've often felt that it helps to understand what has led us to where we are in terms of what we're trying to achieve—that is, well-designed solutions that provide business value and meet all technical and non-technical requirements.
When we architect a system, we must consider many aspects—security, resilience, performance, and more. But why do we need to think of these? At some point, something will go wrong, and therefore we must accommodate that eventuality in our designs.
For this reason, I want to go through a brief history of how technology has changed over the years, how it has affected system design, what new issues have arisen, and—most importantly—how it has changed the role of an IT architect.
We will start in the 1960s when big businesses began to leverage computers to bring efficiencies to their operating models.
Mainframe computing
Older IT systems were monolithic. The first business systems consisted of a large mainframe computer that users interacted with through dumb terminals—simple screens and keyboards with no processing power of their own.
The software that ran on them was often built similarly—they were often unwieldy chunks of code. There is a particularly famous photograph of the National Aeronautics and Space Administration (NASA) computer scientist Margaret Hamilton standing by a stack of printed code that is as tall as she is—this was the code that ran the Apollo Guidance Computer (AGC).
In these systems, the biggest concern was computing resources, and therefore architecture was about managing these resources efficiently. Security was primarily performed by a single user database contained within this monolithic system. While the internet did exist in a primitive way, external communications and, therefore, the security around them didn't come into play. In other words, as the entire solution was essentially one big computer, there was a natural security boundary.
If we examine the following diagram, we can see that in many ways, the role of an architect dealt with fewer moving parts than today, and many of today's complexities, such as security, didn't exist because so much was intrinsic to the mainframe itself:

Figure 1.1 – Mainframe computing
Mainframe computing slowly gave way to personal computing, so next, we will look at how the PC revolution changed systems, and therefore design requirements.
Personal computing
The PC era brought about a business computing model in which you had lower-powered servers that delivered one or two duties—for example, a file server, a print server, or an internal email server.
PCs now connected to these servers over a local network and performed much of the processing themselves.
Early on, each of these servers might have had a user database to control access. However, this was very quickly addressed. The notion of a directory server quickly became the norm so that now we still have a single user database, as in the days of the mainframe; however, the information in that database must control access to services running on other servers.
Security had now become more complex as the resources were distributed, but there was still a naturally secure boundary—that of the local network.
Software also started to become more modular in that individual programs were written to run on single servers that performed discrete tasks; however, these servers and programs might have needed to communicate with each other.
The following diagram shows a typical server-based system whereby individual servers provide discrete services, but all within a corporate network:
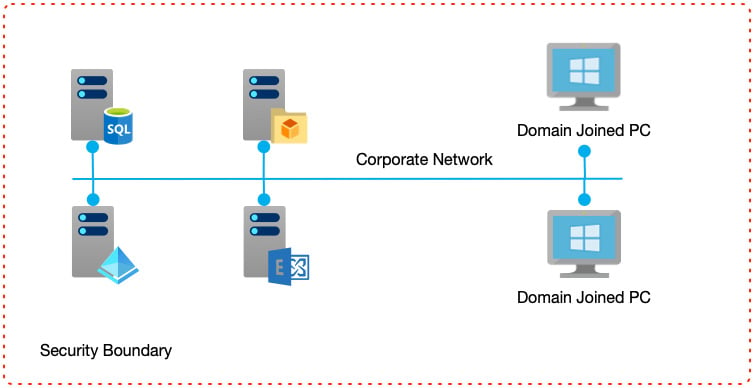
Figure 1.2 – The personal computing era
Decentralizing applications into individual components running on their own servers enabled a new type of software architecture to emerge—that of N-tier architecture. N-tier architecture is a paradigm whereby the first tier would be the user interface, and the second tier the database. Each was run on a separate server and was responsible for providing those specific services.
As systems developed, additional tiers were added—for example, in a three-tier application the database moved to the third tier, and the middle tier encapsulated business logic—for example, performing calculations, or providing a façade over the database layer, which in turn made the software easier to update and expand.
As PCs effectively brought about a divergence in hardware and software design, so too did the role of an architect also split. It now became more common to see architects who specialized in hardware and networking, with responsibilities for communication protocols and role-based security, and software architects who were more concerned with development patterns, data models, and user interfaces.
The lower-cost entry for PCs also vastly expanded their use; now, smaller businesses could start to leverage technologies. Greater adoption led to greater innovation—and one such advancement was to make more efficient use of hardware—through the use of virtualization.
Virtualization
As the software that ran on servers started to become more complex and take on more diverse tasks, it began to become clear that having a server that ran internal emails during the day but was unused in the evening and at the weekend was not very efficient.
Conversely, a backup or report-building server might only be used in the evening and not during the day.
One solution to this problem was virtualization, whereby multiple servers—even those with a different underlying operating system—could be run on the same physical hardware. The key was that physical resources such as random-access memory (RAM) and compute could be dynamically reassigned to the virtual servers running on them.
So, in the preceding example, more resources would be given to the email server during core hours, but would then be reduced and given to backup and reporting servers outside of core hours.
Virtualization also enabled better resilience as the software was no longer tied to hardware. It could move across physical servers in response to an underlying problem such as a power cut or a hardware failure. However, to truly leverage this, the software needed to accommodate it and automatically recover if a move caused a momentary communications failure.
From an architectural perspective, the usual issues remained the same—we still used a single user database directory; virtual servers needed to be able to communicate; and we still had the physically secure boundary of a network.
Virtualization technologies presented different capabilities to design around—centrally shared disks rather than dedicated disks communicating over an internal data bus; faster and more efficient communications between physical servers; the ability to detect and respond to a physical server failing, and moving its resources to another physical server that has capacity.
In the following diagram, we see that discrete servers such as databases, file services, and email servers run as separate virtual services, but now they share hardware. However, from a networking point of view, and arguably a software and security point of view, nothing has changed. A large role of the virtualization layer is to abstract away the underlying complexity so that the operating systems and applications they run are entirely unaware:
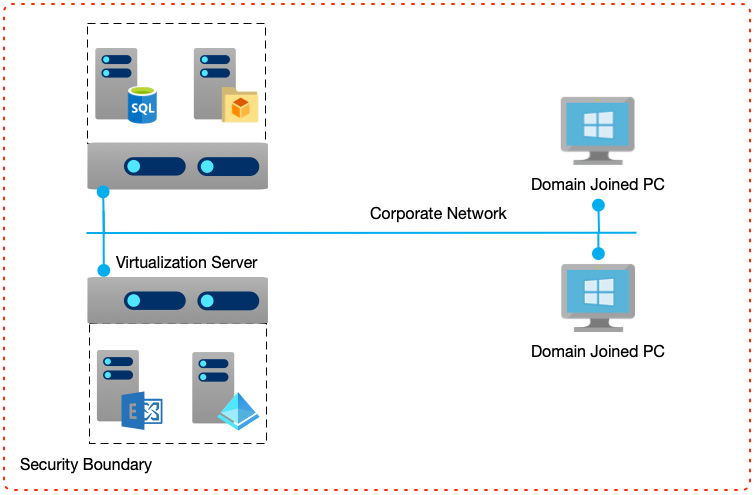
Figure 1.3 – Virtualization of servers
We will now look at web apps, mobile apps, and application programming interfaces (APIs).
Web apps, mobile apps, and APIs
At around the same time, virtualization was starting to grow, and the internet began to mature beyond an academic and military tool. Static, informational websites built purely in HTML gave way to database-driven dynamic content that enabled small start-ups to sell on a worldwide platform with minimal infrastructure.
Websites started to become ever more complex, and slowly the developer community began to realize that full-blown applications could be run as web apps within a browser window, rather than having to control and deploy software directly to a user's PC.
Processing requirements now moved to the backend server—dynamic web pages were generated on the fly by the web server, with the user's PC only rendering the HTML.
With all this reliance on the backend, those designing applications had to take into account how to react to failures automatically. The virtualization layer, and the software running on top, had to be able to respond to issues in a way that made the user completely unaware of them.
Architects had to design solutions to be able to cope with an unknown number of users that may vary over time, coming from different countries. Web farms helped spread the load across multiple servers, but this in itself meant a new way of maintaining state or remembering what a user was doing from one page request to the next, keeping in mind that they might be running on a different server from one request to the next.
As the mobile world exploded, more and more mobile apps needed a way of using a centralized data store—one that could be accessed over the internet. Thus, a new type of web app, the API app, started serving raw data as RESTful services (where REST stands for REpresentational State Transfer) using formats such as Extensible Markup Language (XML) or JavaScript Object Notation (JSON).
Information
A RESTful service is an architectural pattern that uses web services to expose data that other systems can then consume. REST allows systems to interchange data in a pre-defined way. As opposed to an application that communicates directly with a database using database-specific commands and connection types, RESTful services use HTTP/HTTPS with standard methods (GET, POST, DELETE, and so on). This allows the underlying data source to be independent of the actual implementation—in other words, the consuming application does not need to know what the source database is, and in fact could be changed without the need to update the consumer.
Eventually, hosted web sites also started using these APIs, with JavaScript-based frameworks to provide a more fluid experience to users. Ironically, this moved the compute requirements back to the user's PC.
Now, architects have to consider both the capabilities of a backend server and the potential power of a user's device—be it a phone, tablet, laptop, or desktop.
Security now starts to become increasingly problematic for many different reasons.
The first-generation apps mainly used form-based authentication backed by the same database running the app, which worked well for applications such as shopping sites. But as web applications started to serve businesses, users had to remember multiple logins and passwords for all the different systems they use.
As web applications became more popular—being used by corporates, small businesses, and retail customers—ensuring security became equally more difficult. There was no longer a natural internal barrier—systems needed to be accessible from anywhere. As apps themselves needed to be able to communicate to their respective backend APIs, or even APIs from other businesses providing complementary services, it was no longer just users we had to secure, but additional services too.
Having multiple user databases will no longer do the job, and therefore new security mechanisms must be designed and built. OpenID, OAuth2.0, SAML (which stands for Security Assertion Markup Language), and others have been created to address these needs; however, each has its own nuances, and each needs to be considered when architecting solutions. The wrong decision no longer means it won't work; it could mean a user's data being exposed, which in turn leads to massive reputational and financial risk.
From an architectural point of view, solutions are more complex, and as the following diagram shows, the number of components required also increases to accommodate this:
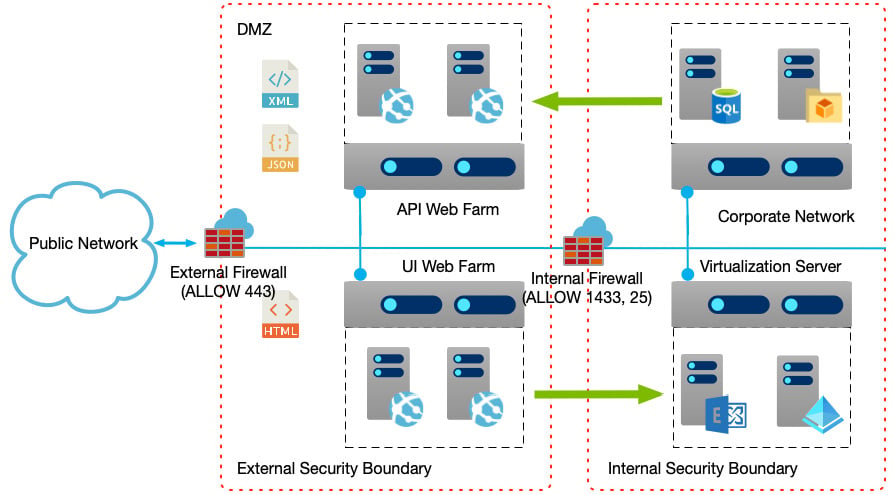
Figure 1.4 – Web apps and APIs increase complexity
Advancements in hardware to support this new era and provide ever more stable and robust systems meant networking, storage, and compute required roles focused on these niche, but highly complex components.
In many ways, this complexity of the underlying hosting platforms led to businesses struggling to cope with or afford the necessary systems and skills. This, in turn, led to our next and final step—cloud computing.
Cloud computing
Cloud platforms such as Azure sought to remove the difficulty and cost of maintaining the underlying hardware by providing pure compute and storage services on a pay-as-you-go or operational expenditure (OpEx) model rather than a capital expenditure (CapEx) model.
So, instead of providing hardware hosting, they offered Infrastructure as a Service (IaaS) components such as VMs, networking and storage, and Platform as a Service (PaaS) components such as Azure Web Apps and Azure SQL Databases. The latter is the most interesting. Azure Web Apps and Azure SQL Databases were the first PaaS offerings. The key difference is that they are services that are fully managed by Microsoft.
Under the hood, these services run on VMs; however, whereas with VMs you are responsible for the maintenance and management of them—patching, backups, resilience—with PaaS, the vendor takes over these tasks and just offers the basic service you want to consume.
Over time, Microsoft has developed and enhanced its service offerings and built many new ones as well. But as an architect, it is vital that you understand the differences and how each type of service has its own configurations, and what impact these have.
Many see Azure as "easy to use", and to a certain extent, one of the marketing points around Microsoft's service is just that—it's easy. Billions of dollars are spent on securing the platform, and a central feature is that the vendor takes responsibility for ensuring the security of its services.
A common mistake made by many engineers, developers, system administrators, and architects is that this means you can just start up a service, such as Azure Web Apps or Azure SQL Databases, and that it is inherently secure "out of the box".
While to a certain extent this may be true, by the very nature of cloud, many services are open to the internet. Every component has its own configuration options, and some of these revolve around securing communications and how they interact with other Azure services.
Now, more than ever, with security taking center stage, an architect must be vigilant of all these aspects and ensure they are taken into consideration. So, whereas the requirement to design underlying hardware is no longer an issue, the correct configuration of higher-level services is critical.
As we can see in the following diagram, the designs of our solutions to a certain extent become more complex in that we must now consider how services communicate between our corporate and cloud networks. However, the need to worry about VMs and hardware disappears—at least when purely using PaaS:

Figure 1.5 – Cloud integration
As we have moved from confined systems such as mainframes to distributed systems with the cloud provider taking on more responsibility, our role as an architect has evolved. Certain aspects may no longer be required, such as hardware design, which has become extremely specialized. However, a cloud architect must simultaneously broaden their range of skills to handle software, security, resilience, and scalability.
For many enterprises, the move to the cloud provides a massive opportunity, but due to existing assets, moving to a provider such as Azure will not necessarily be straightforward. Therefore, let's consider which additional challenges may face an architect when considering migration.