

Characteristics of the new operating model
Understanding how Kubernetes can positively impact IT operations will provide a solid base for the efficient adoption of DevOps in application and infrastructure automation. The following are some of the significant characteristics of the Kubernetes operating model:
- Team collaboration and workflows
- Control theory
- Interoperability
- Extensibility
- New architecture focus
- Open source, community, and governance
Let's look at these characteristics in detail in the following sections.
Important Note
Before we dive deep, it's critical to understand that you are expected to have a basic prior understanding of Kubernetes architecture and its building block resources, such as Pods, Deployments, Services, and namespaces. New to Kubernetes? Looking for a guide to understand the basic concepts? Please go through the documentation at https://kubernetes.io/docs/concepts/overview/.
Team collaboration and workflows
All Kubernetes resources, such as Pods, volumes, Services, Deployments, and Secrets are persistent entities stored in etcd. Kubernetes has well-modeled RESTful APIs to perform CRUD operations over these resources. The Create, Update, and Deletion operations to the etcd persistence store is a state change request. The state change is realized asynchronously with the Kubernetes control plane. There are a couple of characteristics of these Kubernetes APIs that are very useful for efficient team collaboration and workflows:
- Declarative configuration management
- Multi-persona collaboration
Declarative configuration management
We express our automation intent to the Kubernetes API as data points, known as the record of intent. The record does not carry any information about the steps to achieve the intention. This model enables a pure declarative configuration to automate workloads. It is easier to manage automation configuration as data points in Git than code. Also, expressing the automation intension as data is less prone to bugs, and easy to read and maintain. Provided we have a clear Git history, a simple intent expression, and release management, collaboration over the configuration is easy. The following is a simple record of intent for an NGINX Pod deployment:
apiVersion: v1_ kind: Pod metadata: name: proxy spec: containers: - name: proxy-image image: Nginx ports: - name: proxy-port containerPort: 80 protocol: TCP
Even though many new-age automation tools are primarily declarative, they are weak in collaboration because of missing well-modeled RESTful APIs. The following multi-persona collaboration section will discuss this aspect more. The combination of declarative configuration and multi-persona collaboration makes Kubernetes a unique proposition.
Multi-persona collaboration
With Kubernetes or other automation tools, we abstract the data center fully into a single window. Kubernetes has a separate API mapping to each infrastructure concern, unlike other automation tools. Kubernetes groups these concerns under the construct called API groups, of which there are around 20. API groups break the monolith infrastructure resources into minor responsibilities, providing segregation for different personas to operate an infrastructure based on responsibility. To simplify, we can logically divide the APIs into five sections:
- Workloads are objects that can help us to manage and run containers in the Kubernetes cluster. Resources such as Pods, Deployments, Jobs, and StatefulSets belong to the
workloadcategory. These resources mainly come under theappsandcoreAPI groups. - Discovery and load balancers is a set of resources that helps us stitch workloads with load balancers. People responsible for traffic management can have access to these sets of APIs. Resources such as Services, NetworkPolicy, and Ingress appear under this category. They fall under the
coreandnetworking.k8s.ioAPI groups. - Config and storage are resources helpful to manage initialization and dependencies for our workloads, such as ConfigMaps, Secrets, and volumes. They fall under the
coreandstorage.k8s.io APIgroups. The application operators can have access to these APIs. - Cluster resources help us to manage the Kubernetes cluster configuration itself. Resources such as Nodes, Roles,
RoleBinding,CertificateSigningCertificate,ServiceAccount, and namespaces fall under this category, and cluster operators should access these APIs. These resources come under many API groups, such ascore,rbac,rbac.authorization.k8s.io, andcertificates.k8s.io. - Metadata resources are helpful to specify the behavior of a workload and other resources within the cluster. A HorizontalPodAutoScaler is a typical example of metadata resources defining workload behavior under different load conditions. These resources can fall under the
core,autoscaling, andpolicyAPI groups. People responsible for application policies or automating architecture characteristics can access these APIs.
Note that the core API group holds resources from all the preceding categories. Explore all the Kubernetes resources yourself with the help of the kubectl comments. A few comment examples are as follows:
# List all resources kubectl api-resources # List resources in the "apps" API group kubectl api-resources --api-group=apps # List resources in the "networking.k8s.io" API group kubectl api-resources --api-group=networking.k8s.io
The following screenshots give you a quick glimpse of resources under the apps and networking.k8s.io API groups, but I would highly recommend playing around to look at all resources and their API groups:

Figure 1.2 – Resources under the apps API group
The following are the resources under the network.k8s.io API group:

Figure 1.3 – Resources under the network.k8s.io API group
We can assign RBAC for teams based on individual resources or API groups. The following diagram represents the developers, application operators, and cluster operators collaborating over different concerns:

Figure 1.4 – Team collaboration
This representation may vary for you, based on an organization's structure, roles, and responsibilities. Traditional automation tools are template-based, and it's difficult for teams to collaborate. It leads to situations where policies are determined and implemented by two different teams. Kubernetes changed this operating model by enabling different personas to collaborate directly by bringing down the friction in collaboration.
Control theory
Control theory is a concept from engineering and mathematics, where we maintain the desired state in a dynamic system. The state of a dynamic system changes over time with the environmental changes. Control theory executes a continuous feedback loop to observe the output state, calculate the divergence, and then control input to maintain the system's desired state. Many engineering systems around us work using control theory. An air conditioning system with a continuous feedback loop to maintain temperature is a typical example. The following illustration provides a simplistic view of control theory flow:

Figure 1.5 – Control theory flow
Kubernetes has a state-of-the-art implementation of control theory. We submit our intention of the application's desired state to the API. The rest of the automation flow is handled by Kubernetes, marking an end to the human workflow once the API is submitted. Kubernetes controllers run a continuous reconciliation loop asynchronously to ensure that the desired state is maintained across all Kubernetes resources, such as Pods, Nodes, Services, Deployments, and Jobs. The controllers are the central brain of Kubernetes, with a collection of controllers responsible for managing different Kubernetes resources. Observe, analyze, and react are the three main functions of an individual controller:
- Observe: Events relevant to the controller's resources are received by the observer. For example, a deployment controller will receive all the deployment resource's
create,delete, andupdateevents. - Analyze: Once the observer receives the event, the analyzer jumps in to compare the current and desired state to find the delta.
- React: Performs the needed action to bring the resources back into the desired state.
The control theory implementation in Kubernetes changed the way IT performs in day one and day two operations. Once we express our intention as data points, the human workflow is over. The machine takes over the operations in asynchronous mode. Drift management is no longer part of the human workflow. In addition to the existing controllers, we can extend Kubernetes with new controllers. We can easily encode any operational knowledge required to manage our workload into a custom controller (operators) and hand over the custom day two operations to machines:
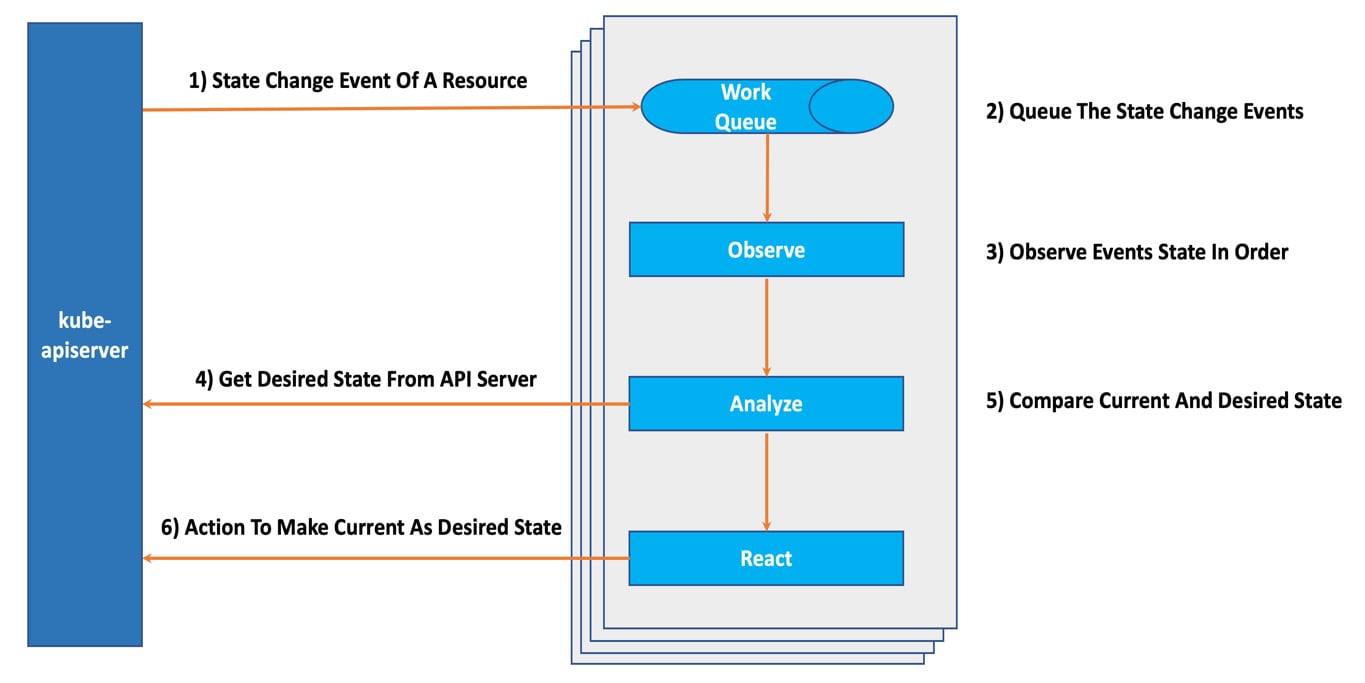
Figure 1.6 – The Kubernetes controller flow
Interoperability
The Kubernetes API is more than just an interface for our interaction with the cluster. It is the glue holding all the pieces together. kubectl, the schedulers, kubelet, and the controllers create and maintain resources with the help of kube-apiserver. kube-apiserver is the only component that talks to the etcd state store. kube-apiserver implements a well-defined API interface, providing state observability from any Kubernetes component and outside the cluster. This architecture of kube-apiserver makes it interoperable with the ecosystem. Other infrastructure automation tools such as Terraform, Ansible, and Puppet do not have a well-defined API to observe the state.
Take observability as an example. Many observability tools evolved around Kubernetes because of the interoperable characteristic of kube-apiserver. For contemporary digital organizations, continuous observability of state and a feedback loop based on it is critical. End-to-end visibility in the infrastructure and applications from the perspective of different stakeholders provides a way to realize operational excellence. Another example of interoperability is using various configuration management tools, such as Helm as an alternative to kubectl. As the record of intent is pure YAML or JSON data points, we can easily interchange one tool with another. The following diagram provides a view of kube-apiserver interactions with other Kubernetes components:
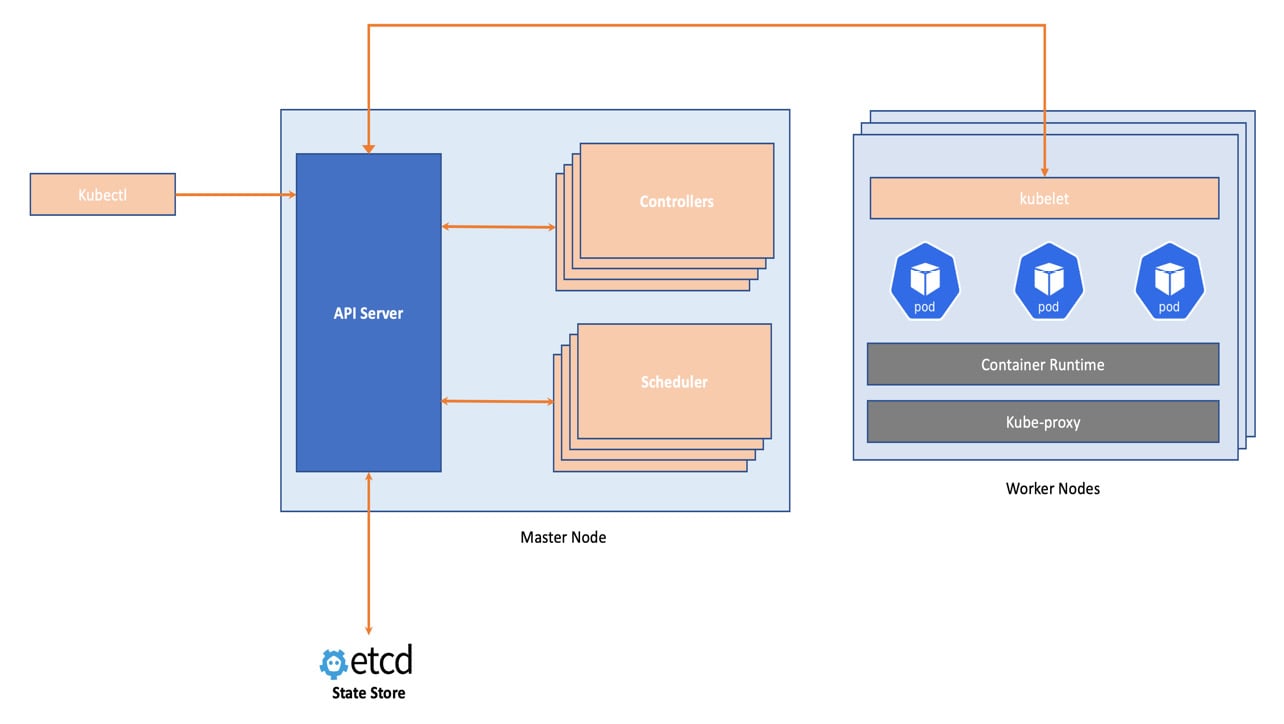
Figure 1.7 – Kubernetes API interactions
Interoperability means many things to IT operations. Some of the benefits are as follows:
- Easy co-existence with the organization ecosystem.
- Kubernetes itself will evolve and be around for longer.
- Leveraging an existing skill set by choosing known ecosystem tools. For example, we can use Terraform for Kubernetes configuration management to take advantage of a team's knowledge in Terraform.
- Hypothetically keeping the option open for migrating away from Kubernetes in the future. (Kubernetes APIs are highly modular, and we can interchange the underlying components easily. Also, a pure declarative config is easy to migrate away from Kubernetes if required.)
Extensibility
Kubernetes' ability to add new functionalities is remarkable. We can look at the extensibility in three different ways:
- Augmenting Kubernetes core components
- Interchangeability of components
- Adding new resource types
Augmented Kubernetes core components
This extending model will either add additional functionality to the core components or alter core component functionality. We will look at a few examples of these extensions:
- kubectl plugins are a way to attach sub-commands to the
kubectlCLI. They are executables added to an operator's computer in a specific format without changing thekubectlsource in any form. These extensions can combine a process that takes several steps into a single sub-command to increase productivity. - Custom schedulers are a concept that allows us to modify Kubernetes' resource scheduling behavior. We can even register multiple schedulers to run parallel to each other and configure them for different workloads. The default scheduler can cover most of the general use cases. Custom schedulers are needed if we have a workload with a unique scheduling behavior not available in the default scheduler.
- Infrastructure plugins are concepts that help to extend underlying hardware. The device, storage, and network are the three different infrastructure plugins. Let's say a device supports GPU processing – we require a mechanism to advertise the GPU usage details to schedule workload based on GPU.
Interchangeability of components
The interoperability characteristics of Kubernetes provide the ability to interchange one core component with another. These types of extensions bring new capabilities to Kubernetes. For example, let's pick up the virtual kubelet project (https://github.com/virtual-kubelet/virtual-kubelet). Kubelet is the interface between the Kubernetes control plane and the virtual machine nodes where the workloads are scheduled. Virtual kubelet mimics a node in the Kubernetes cluster to enable resource management with infrastructure other than a virtual machine node such as Azure Container Instances or AWS Fargate. Replacing the Docker runtime with another container runtime environment such as Rocket is another example of interchangeability.
Adding new resource types
We can expand the scope of the Kubernetes API and controller to create a new custom resource, also known as CustomResourceDefinition (CRD). It is one of the powerful constructs used for extending Kubernetes to manage resources other than containers. Crossplane, a platform for cloud resource management, falls under this category, which we will dive deep into in the upcoming chapters. Another use case is to automate our custom IT day one and day two processes, also known as the operator pattern. For example, tasks such as deploying, upgrading, and responding to failure can be encoded into a new Kubernetes operator.
People call Kubernetes a platform to build platforms because of its extensive extendibility. They generally support new use cases or make Kubernetes fit into a specific ecosystem. Kubernetes presents itself to IT operations as a universal abstraction by extending and supporting every complex deployment environment.
Architecture focus
One of the focuses of architecture work is to make the application deployment architecture robust to various conditions such as virtual machine failures, data center failures, and diverse traffic conditions. Also, resource utilization should be optimum without any wastage of cost in over-provisioned infrastructure. Kubernetes makes it simple and unifies how to achieve architecture characteristics such as reliability, scalability, availability, efficiency, and elasticity. It relieves architects from focusing on infrastructure. Architects can now focus on building the required characters into the application, as achieving them at the infrastructure level is not complex anymore. It is a significant shift in the way traditional IT operates. Designing for failure, observability, and chaos engineering practices are becoming more popular as areas for architects to concentrate onin the world of containers.
Portability is another architecture characteristic Kubernetes provides to workloads. Container workloads are generally portable, but dependencies are not. We tend to introduce dependencies with other cloud components. Building portability into application dependencies is another architecture trend in recent times. It's visible with the 2021 InfoQ architecture trends (https://www.infoq.com/articles/architecture-trends-2021/). In the trend chart, design for portability, Dapar, the Open Application Model, and design for sustainability are some of the trends relevant to workload portability. We are slowly moving in the direction of portable cloud providers.
With the deployment of workloads into Kubernetes, our focus on architecture in the new IT organization has changed forever.
Open source, community, and governance
Kubernetes almost relieves people from working with machines. Investing in such a high-level abstraction requires caution, and we will see whether the change will be long-lasting. Any high-level abstraction becoming a meaningful and long-lasting change requires a few characteristics. Being backed by almost all major cloud providers, Kubernetes has those characteristics. The following are the characteristics that make Kubernetes widely accepted and adopted.
Project ownership
Project ownership is critical for an open source project to succeed and drive universal adoption. A widely accepted foundation should manage open source projects rather than being dominated by an individual company, and the working group driving the future direction should have representations from a wide range of companies. It will reflect the neutrality of the project, where every stakeholder can participate and benefit from the initiative. Kubernetes fits very well into this definition. Even though Kubernetes originated from a project by a few Google engineers, it soon became part of the Cloud Native Computing Foundation (CNCF). If we look at the governing board and members of the CNCF, we can see that there is representation from all top technology firms (https://www.cncf.io/people/governing-board/ & https://www.cncf.io/about/members/). Kubernetes also has special interest groups and working groups and is also represented by many technology companies, including all cloud providers.
Contribution
Kubernetes is one of the high-velocity projects in GitHub, with more than 3,000 contributors. With a high velocity of commits from the community, Kubernetes looks sustainable. Also, there is a high volume of documentation, books, and tutorials available. Above all, we have too many ecosystem tools and platforms evolving around Kubernetes. It makes developing and deploying workloads on Kubernetes easier.
Open standards
As the scope of Kubernetes abstraction is not tiny, it did not attempt to solve all the problems by itself. Instead, it depended on a few open standards to integrate existing widely accepted tools. It also encouraged the ecosystem to develop new tools aligning to open standards. For example, Kubernetes can work with any container runtimes such as Docker and Rocker, which comply with the standard Container Runtime Interface (CRI). Similarly, any networking solution that complies with the Container Networking Interface (CNI) can be a networking solution for Kubernetes.
Kubernetes' method of open source governance provides a few advantages to IT operations:
- Kubernetes is sustainable and organizations can invest confidently.
- Wider adoption will maintain a strong talent pool.
- Strong community support.
The preceding section concludes the critical aspects of the new Kubernetes IT operating model. While we have looked at the benefits of every individual characteristic, we also have advantages when we combine them. For example, platforms such as Crossplane are evolving by taking advantage of the multiple aspects discussed previously.