

Cassandra has three containers, one within another. The outermost container is Keyspace. You can think of Keyspace as a database in the RDBMS land. Next, you will see the column family, which is like a table. Within a column family are columns, and columns live under rows. Each row is identified by a unique row key, which is like the primary key in RDBMS.
The Cassandra data model
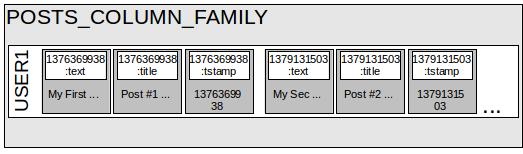
Things were pretty monotonous until now, as you already knew everything that we talked about from RDBMS. The difference is in the way Cassandra treats this data. Column families, unlike tables, can be schema free (schema optional). This means you can have different column names for different rows within the same column family. There may be a row that has user_name, age, phone_office, and phone_home, while another row can have user_name, age, phone_office, office_address, and email. You can store about two billion columns per row. This means it can be very handy to store time series data, such as tweets or comments on a blog post. The column name can be a timestamp of these events. In a row, these columns are sorted by natural order; therefore, we can access the time series data in a chronological or reverse chronological order, unlike RDBMS, where each row just takes the space as per the number of columns in it. The other difference is, unlike RDBMS, Cassandra does not have relations. This means relational logic will be needed to be handled at the application level. This means we may want to denormalize things because there is no join.
Rows are identified by a row key. These row keys act as partitioners. Rows are distributed across the cluster, creating effective auto-shading. Each server holds a range(s) of keys. So, if balanced, a server with more nodes will have a fewer number of rows per node. All these concepts will be repeated in detail in the later chapters.