

There is no better way to learn a technology than doing a proof of concept with it. This section will work on a very simple application to get you familiarized with Cassandra. We will build the backend of a simple blogging application where a user can:
Create a blogging account
Publish posts
Have people comment on those posts
Have people upvote or downvote a post or a comment
In the RDBMS world, you would glance over the entities and think about relations while modeling the application. Then you will join tables to get the required data. There is no join in Cassandra. So, we will have to denormalize things. Looking at the previously mentioned specifications, we can say that:
We need a blog metadata column family to store the blog name and other global information, such as the blogger's username and password.
We will have to pull posts for the blog. Ideally, sorted in reverse chronological order.
We will also have to pull all the comments for each post when we are seeing the post page.
We will also have to have counters for the upvotes and downvotes for posts and comments.
So, we can have a blog metadata column family for fixed user attributes. With posts, we can do many things, such as the following:
We can have a dynamic column family of super type (super column family—a super column is a column that holds columns), where a row key is the same as a user ID. The column names are timestamps for when the post was published, and the columns under the super column hold attributes of the post, which include the title, text, author's name, time of publication, and so on. But this is a bad idea. I recommend that you don't use super columns. We will see super columns and why it is not preferred in the Avoid super columns section in Chapter 3, Design Patterns.
We can use composite columns in place of super columns. You can think of a composite column as a row partitioned in chunks by a key. For example, we take a column family that has
CompositeTypecolumns, where the two types that make a composite column areLongType(for timestamp) andUTF8Type(for attributes). We can pull posts grouped by the timestamp, which will have all the attributes.See the following figure. If it is too confusing as of now, do not worry; we will cover this in detail later.
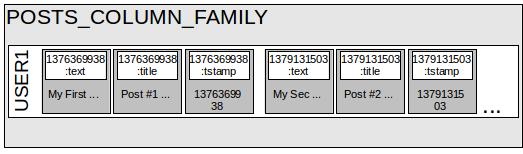
Writing time series grouped data using composite columns
Although a composite column family does the job of storing posts, it is not ideal. A couple of things to remember:
A row can have a maximum of two billion columns. If each post is denoted by three attributes, a user can post a maximum of two-thirds of a billion posts, which might be OK. And if it is not, we still have solutions.
We can bucket the posts. For example, we just store the posts made in a month, in one row. We will cover the concept of bucketing later.
The other problem with this approach is that an entire row lives on one machine. The disk must be large enough to store the data.
In this particular case, we need not be worried about this. The problem is something else. Let's say a user has very popular posts and is responsible for 40 percent of the total traffic. Since we have all the data in a single row, and a single row lives on a single machine (and the replicas), those machines will be queried 40 percent of the time. So, if you have a replication factor of two, and there are 20 Cassandra servers, the two servers that hold the particular blog will be serving more than 40 percent of the reads. This is called a hotspot.
It would be a good idea to share the posts across all the machines. This means we need to have one post per row (because rows are shared). This will make sure that the data is distributed across all the machines, and hence avoid hotspots and the fear of getting your disk out of space. We wouldn't be limited by a two-billion limit either.
But, now we know that the rows are not sorted. We need our posts to be arranged by time. So, we need a row that can hold the row keys of the posts in a sorted order. This again brings the hotspot and the limit of two billion. We may have to avoid it by some sort of bucketing, depending on what the demand of the application is.
So, we have landed somewhere similar to what we would have in a RDBMS posts column family. It's not necessary that we always end up like this. You need to consider what the application's demand is and accordingly design the things around that.
Similar to the post, we have comment. Unlike posts, comments are associated with posts and not the user. Then we have upvotes and downvotes. We may have two counter column families for post votes and comment votes, each holding the upvotes and downvotes columns.

Schema based on the discussion
The bold letters in the preceding diagram refer to the row keys. You can think of a row key as the primary key in a database. There are two dynamic or wide row column families: blog_posts and post_comments. They hold the relationship between a blog and its posts, and a post with its comments, respectively. These column families have column names as timestamps and the values that these columns store is the row key to the posts and comments column families, respectively.
Time to start something tangible! In this section, we will see how to get a working code for the preceding schema. Our main goal is to be able to create a user, write a post, post a comment, upvote and downvote them, and to fetch the posts. The code in this section and in many parts of this book is in Python—the reason being Python's conciseness, readability, and easy-to-understand approach (XKCD – Python, http://xkcd.com/353/). Python is an executable pseudocode (Thinking in Python – Python is executable pseudocode. Perl is executable line noise. http://mindview.net/Books/Python/ThinkingInPython.html). Even if you have never worked in Python or do not want to use Python, the code should be easy to understand. So, we will use Pycassa, a Python client for Cassandra. In this example, we will not use CQL 3, as it is still in beta in Cassandra 1.1.11. You may learn about CQL3 in Chapter 9, Introduction to CQL 3 and Cassandra 1.2, and about Pycassa from its GitHub repository at http://pycassa.github.io/pycassa/.
Setting up involves creating a keyspace and a column family. It can be done via cassandra-cli or cqlsh or the Cassandra client library. We will see how this is done using cassandra-cli later in this book, so let's see how we do it programmatically using Pycassa. For brevity, the trivial parts of the code are not included.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www. packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you, or from the author's Github page at https://github.com/naishe/mastering_cassandra.
SystemManager is responsible for altering schema. You connect to a Cassandra node, and perform schema tweaks.
from pycassa.system_manager import *
sys = SystemManager('localhost:9160')Creating a keyspace requires some options to be passed on. Do not worry about them at this point. For now, think about the following code, as it sets the simplest configurations for a single node cluster that is good for a developer laptop:
sys.create_keyspace('blog_ks', SIMPLE_STRATEGY, {'replication_factor': '1'})Creating a column family requires you to pass a keyspace and column family name; the rest are set to default. For static column families (the ones having a fixed number of columns), we will set column names. Other important parameters are row key type, column name type, and column value types. So, here is how we will create all the column families:
# Blog metadata column family (static)
sys.create_column_family('blog_ks', 'blog_md', comparator_type=UTF8_TYPE, key_validation_class=UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'name', UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'email', UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'password', UTF8_TYPE)
# avoiding keystrokes by storing some parameters in a variable
cf_kwargs0 = {'key_validation_class': TIME_UUID_TYPE, 'comparator_type':UTF8_TYPE}
# Posts column family (static)
sys.create_column_family('blog_ks', 'posts', **cf_kwargs0)
sys.alter_column('blog_ks', 'posts', 'title', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'text', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'blog_name', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'author_name', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'timestamp', DATE_TYPE)
# Comments column family (static)
sys.create_column_family('blog_ks', 'comments', **cf_kwargs0)
sys.alter_column('blog_ks', 'comments', 'comment', UTF8_TYPE)
sys.alter_column('blog_ks', 'comments', 'author', UTF8_TYPE)
sys.alter_column('blog_ks', 'comments', 'timestamp', DATE_TYPE)
# Create a time series wide column family to keep comments
# and posts in chronological order
cf_kwargs1 = {'comparator_type': LONG_TYPE, 'default_validation_class': TIME_UUID_TYPE, 'key_validation_class': UTF8_TYPE}
cf_kwargs2 = {'comparator_type': LONG_TYPE, 'default_validation_class': TIME_UUID_TYPE, 'key_validation_class': TIME_UUID_TYPE}
sys.create_column_family('blog_ks', 'blog_posts', **cf_kwargs1)
sys.create_column_family('blog_ks', 'post_comments', **cf_kwargs2)
# Counters for votes (static)
cf_kwargs = {'default_validation_class':COUNTER_COLUMN_TYPE, 'comparator_type': UTF8_TYPE, 'key_validation_class':TIME_UUID_TYPE }
# Blog vote counters
sys.create_column_family('blog_ks', 'post_votes', **cf_kwargs)
sys.alter_column('blog_ks', 'post_votes', 'upvotes', COUNTER_COLUMN_TYPE)
sys.alter_column('blog_ks', 'post_votes', 'downvotes', COUNTER_COLUMN_TYPE)
# Comments votes counter
sys.create_column_family('blog_ks', 'comment_votes', **cf_kwargs)
sys.alter_column('blog_ks', 'comment_votes', 'upvotes', COUNTER_COLUMN_TYPE)
sys.alter_column('blog_ks', 'comment_votes', 'downvotes', COUNTER_COLUMN_TYPE)We are done with setting up. A couple of things to remember:
A static column family does not restrict you to storing arbitrary columns.
As long as the validation satisfies, you can store and fetch data.
Wouldn't it be nice if you could have the votes column sitting next to the posts column and the comments column? Unfortunately, counter columns do not mix with any other types. So, we need to have a separate column family.
This section discusses a very basic blog application. The code sample included here will show you the basic functionality. It is quite easy to take it from here and start building an application of your own. In a typical application, you'd initialize a connection pool at the start of the application. Use it for the lifetime of the application and close it when your application shuts down. Here is some initialization code:
from pycassa.pool import ConnectionPool from pycassa.columnfamily import ColumnFamily from pycassa.cassandra.ttypes import NotFoundException import uuid, time from Markov import Markov from random import randint, choice cpool = ConnectionPool(keyspace='blog_ks', server_list=['localhost:9160']) blog_metadata = ColumnFamily(cpool, 'blog_md') posts = ColumnFamily(cpool, 'posts') comments = ColumnFamily(cpool, 'comments') blog_posts = ColumnFamily(cpool, 'blog_posts') post_comments = ColumnFamily(cpool, 'post_comments') post_votes = ColumnFamily(cpool, 'post_votes') comment_votes = ColumnFamily(cpool, 'comment_votes')
Create a new blog using the following code:
def add_blog(blog_name, author_name, email, passwd):
blog_metadata.insert(blog_name, {'name': author_name, 'email': email, 'password': passwd})Insert a new post and comment using the following code:
def add_post(title, text, blog_name, author_name):
post_id = uuid.uuid1()
timestamp = int(time.time() * 1e6 )
posts.insert(post_id, {'title':title, 'text': text, 'blog_name': blog_name, 'author_name': author_name, 'timestamp':int(time.time())})
blog_posts.insert(blog_name, {timestamp: post_id})
return post_id
def add_comment(post_id, comment, comment_auth):
comment_id = uuid.uuid1()
timestamp = int(time.time() * 1e6)
comments.insert(comment_id, {'comment': comment, 'author': comment_auth, 'timestamp': int(time.time())})
post_comments.insert(post_id, {timestamp: comment_id})
return comment_idNot having a relational setup in Cassandra, you have to manage relationships on your own. We insert the data in a posts or comments column family and then add this entry's key to another column family that has the row key as a blog name and the data sorted by their timestamp. This does two things: one, we can read all the posts for a blog if we know the blog name. The other fringe benefit of this is that we have post IDs sorted in a chronological order. So, we can pull posts ordered by the date of creation.
Updating vote counters is as easy as mentioned in the following code:
def vote_post(post_id, downvote = False): if(downvote): post_votes.add(post_id, 'downvotes') else: post_votes.add(post_id, 'upvotes') def vote_comment(comment_id, downvote = False): if(downvote): comment_votes.add(comment_id, 'downvotes') else: comment_votes.add(comment_id, 'upvotes')
With all this done, we are able to do all the creation-related stuff. We can create a blog, add a post, comment on it, and upvote or downvote posts or comments. Now, a user visiting the blog may want to see the list of posts. So, we need to pull out the latest 10 posts and show them to the user. However, it is not very encouraging to a visitor if you just list 10 blog posts spanning a really lengthy page to scroll. We want to keep it short, interesting, and a bit revealing. If we just show the title and a small part of the post, we have fixed the scroll issue. The next thing is making it interesting. If we show the number of upvotes and downvotes to a post, a visitor can quickly decide whether to read the post, based on the votes. The other important piece is the number of comments that each post has received. It is an interesting property that states that the more comments, the more interesting a post is.
Ultimately, we have the date when the article was written. A recent article is more attractive than an older one on the same topic. So, we need to write a getter method that pulls a list with all this information. Here is how we go about it:
def get_post_list(blog_name, start='', page_size=10):
next = None
# Get latest page_size (10) items starting from “start†column name
try:
# gets posts in reverse chronological order. The last column is extra.
# It is the oldest, and will have lowest timestamp
post_ids = blog_posts.get(blog_name, column_start = start, column_count = page_size+1, column_reversed = True)
except NotFoundException as e:
return ([], next)
# if we have items more than the page size, that means we have the next item
if(len(post_ids) > page_size):
#get the timestamp of the oldest item, it will be the first item on the next page
timestamp_next = min(post_ids.keys())
next = timestamp_next
# remove the extra item from posts to show
del post_ids[timestamp_next]
# pull the posts and votes
post_id_vals = post_ids.values()
postlist = posts.multiget(post_id_vals)
votes = post_votes.multiget(post_id_vals)
# merge posts and votes and yeah, trim to 100 chars.
# Ideally, you'd want to strip off any HTML tag here.
post_summary_list = list()
for post_id, post in postlist.iteritems():
post['post_id'] = post_id
post['upvotes'] = 0
post['downvotes'] = 0
try:
vote = votes.get(post_id)
if 'upvotes' in vote.keys():
post['upvotes'] = vote['upvotes']
if 'downvotes' in vote.keys():
post['downvotes'] = vote['downvotes']
except NotFoundException:
pass
text = str(post['text'])
# substringing to create a short version
if(len(text) > 100):
post['text'] = text[:100] + '... [Read more]'
else:
post['text'] = text
comments_count = 0
try:
comments_count = post_comments.get_count(post_id)
except NotFoundException:
pass
post['comments_count'] = comments_count
# Note we do not need to go back to blog metadata CF as we have stored the values in posts CF
post_summary_list.append(post)
return (post_summary_list, next)This is probably the most interesting piece of code till now with a lot of things happening. First, we pull the list of the latest 10 post_id values for the given blog. We use these IDs to get all the posts and iterate in the posts. For each post, we pull out the number of upvotes and downvotes. The text column is trimmed to 100 characters. We also get the count of comments. These items are packed and sent back.
One key thing is the next variable. This variable is used for pagination. In an application, when you have more than a page size of items, you show the previous and/or next buttons. In this case, we slice the wide row that holds the timestamp and post_ids values in chunks of 10. As you can see the method signature, it needs the starting point to pull items. In our case, the starting point is the timestamp of the post that comes next to the last item of this page.
The actual code simulates insertions and retrievals. It uses the Alice in Wonderland text to generate a random title, content and comments, and upvotes and downvotes. One of the simulation results the following output as a list of items:
ITS DINNER, AND ALL ASSOCIATED FILES OF FORMATS [votes: +16/-8] Alice ventured to ask. 'Suppose we change the subject,' the March Hare will be linked to the general... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [8 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- THEM BACK AGAIN TO THE QUEEN, 'AND HE TELL [votes: +9/-4] were using it as far as they used to say "HOW DOTH THE LITTLE BUSY BEE," but it all is! I'll try and... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [7 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- GET SOMEWHERE,' ALICE ADDED AN [votes: +15/-6] Duchess sang the second copy is also defective, you may choose to give the prizes?' quite a new kind... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [10 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- SHE WOULD KEEP, THROUGH ALL HER COAXING. HARDLY WHAT [votes: +14/-0] rising to its feet, 'I move that the way out of the sea.' 'I couldn't afford to learn it.' said the ... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [12 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * --
Once you understand this, the rest is very simple. If you wanted to show a full post, use post_id from this list and pull the full row from the posts column family. With all the other fetchings (votes, title, and so on) similar to the aforementioned code, we can pull all the comments on the post and fetch the votes on each of the comments. Deleting a post or a comment requires you to manually delete all the relationships that we made during creation. Updates are similar to insert.