As we have seen there are a number of different types of deployment we could use, which one you choose really depends on our application's make up. Each has a number of trade-offs but most deployments tend to use one of the first two, with the client and server cluster approach the usual favorite unless we have a mostly compute focused application where the former is a simpler set up.
So let's have a look at the various architectural setups we could employ and what situations they are best suited to.
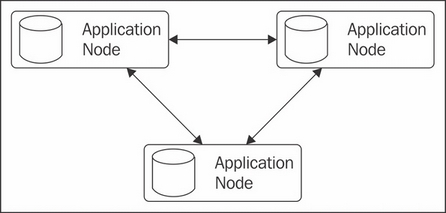
This is the standard example we have been mostly using until now, each node houses both our application itself, and data persistence and processing. It is most useful when we have an application that is primarily focused towards asynchronous or high performance computing, and will be executing lots of tasks on the cluster. The greatest drawback is the inability to scale our application and data capacity separately.