

Often, we have to present two data sources and compare them as if they were one. A typical example of this type of situation is the comparison of budget data to actuals. More often than not, the budgets are prepared at a much higher-level of grain than of actual data.
Consider the sales data that has been used in this chapter. We may define the grain of this as Reseller, Date, and Product. The actual grain of the table is, of course, a lower-level since it includes additional fields such as Sales Order and Geography, but for our purposes, this is the grain that we have chosen to present to the model user. Now, consider some high-level budget data that simply shows the budgeted sales (USD Gross Sales) by Quarter and Year. Our goal is to incorporate this into the model. Have a look at the following screenshot:
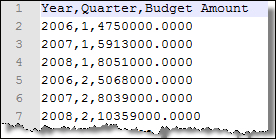
There are two common approaches that are commonly used to solve this problem. Firstly, the original data is arbitrarily assigned to a member within...