If you need to create a dataset with data coming from a database, you can do it just by using a
Table Input step. If the SELECT statement that retrieves the data doesn't need parameters, you simply write it in the Table Input setting window and proceed. However, most of the times you need flexible queries—queries that receive parameters. This recipe will show you how to pass parameters to a SELECT statement in PDI.
Assume that you need to list all products in Steel Wheels for a given product line and scale.
Perform the following steps to connect to a database with parameters:
Create a transformation.
Before getting the data from the database, you have to create the stream that will provide the parameters for the statement.
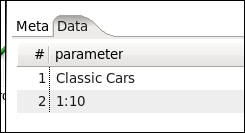
Create a stream that builds a dataset with a single row and two columns: the product line parameter and the scale parameter. For this exercise, we will be using a Data Grid step, but other steps like the Generate Rows step will also work. Opening the Data Grid step, add the
productline_parandproductscale_parlines to the Meta tab. They should both be of type String:
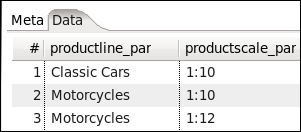
Switch to the Data tab. Notice how the fields created in the Meta tab build the row for data to be added to. Create a record with
Classic Carsas the value forproductline_parand1:10as the value forproductscale_par:
Now drag a Table Input step to the canvas and create a hop from the Data Grid step, which was created previously, towards this step.
Now you can configure the Table Input step. Double-click on it, select the connection to the database, and type in the following statement:
SELECT PRODUCTLINE , PRODUCTSCALE , PRODUCTCODE , PRODUCTNAME FROM PRODUCTS p WHERE PRODUCTLINE = ? AND PRODUCTSCALE = ?Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
In the Insert data from step list, select the name of the step that is linked to the Table Input step. Close the window.
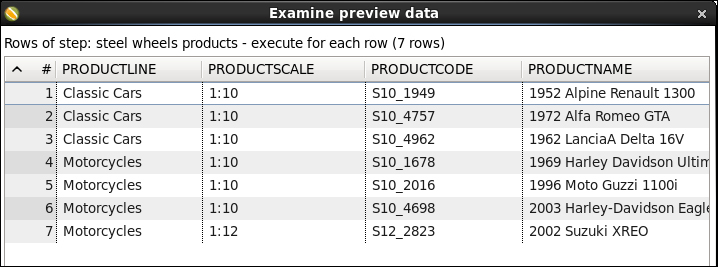
Select the Table Input step and do a preview of the transformation. You will see a list of all products that match the product line and scale provided in the incoming stream:

When you need to execute a SELECT statement with parameters, the first thing you have to do is to build a stream that provides the parameter values needed by the statement. The stream can be made of just one step; for example, a data grid with fixed values, or a stream made up of several steps. The important thing is that the last step delivers the proper values to the Table Input step.
Then, you have to link the last step in the stream to the Table Input step where you will type the statement. What differentiates this statement from a regular statement is that you have to provide question marks. When you preview or run the transformation, the statement is prepared and the values coming to the Table Input step are bound to the placeholders; that is, the place where you typed the question marks.
Note that in the recipe the output of the stream was a single row with two fields, which is exactly the same number of question marks as in the statement.
Note
The number of fields coming to a Table Input step must be exactly the same as the number of question marks found in the query.
Also note that in the stream, the product line was in the first place and the product scale in the second place. If you look at the highlighted lines in the recipe, you will see that the statement expected the parameter values to be exactly in that order.
Note
The replacement of the markers respects the order of the incoming fields.
Any values that are used in this manner are consumed by the Table Input step. Finally, it's important to note that question marks can only be used to parameterize value expressions just as you did in the recipe.
Keywords or identifiers (for example; table names) cannot be parameterized with the question marks method.
If you need to parameterize something different from a value expression, you should take another approach, as explained in the next recipe.
There are a couple of situations worth discussing.
In the recipe you received the list of parameter values in a single row with as many columns as expected parameter values. It's also possible to receive the parameter values in several rows. If, instead of a row you had one parameter by row, as shown in the following screenshot, the behavior of the transformation wouldn't have changed:
The statement would have pulled the values for the two parameters from the incoming stream in the same order as the data appeared. It would have bound the first question mark with the value in the first row, and the second question mark with the value coming in the second row.
Note that this approach is less flexible than the previous one. For example, if you have to provide values for parameters with different data types, you will not be able to put them in the same column and different rows.
Suppose that you not only want to list the Classic Cars in 1:10 scale, but also the Motorcycles in 1:10 and 1:12 scales. You don't have to run the transformation three times in order to do this. You can have a dataset with three rows, one for each set of parameters, as shown in the following screenshot:
Then, in the Table Input setting window you have to check the Execute for each row? option. This way, the statement will be prepared and the values coming to the Table Input step will be bound to the placeholders, once for each row in the dataset coming to the step. For this example, the result would look like the following: