

Evaluation is incredibly important in building solid NLP systems. It allows developers and management to map a business need to system performance, which, in turn, helps communicate system improvement to vested parties. "Well, uh, the system seems to be doing better" does not hold the gravitas of "Recall has improved 20 percent, and the specificity is holding well with 50 percent more training data".
This recipe provides the steps for the creation of truth or gold standard data and tells us how to use this data to evaluate the performance of our precompiled classifier. It is as simple as it is powerful.
You might have noticed the headers from the output of the CSV writer and the suspiciously labeled column, TRUTH. Now, we get to use it. Load up the tweets we provided earlier or convert your data into the format used in our .csv format. An easy way to get novel data is to run a query against Twitter with a multilingual friendly query such as Disney, which is our default supplied data.
Open the CSV file and annotate the language you think the tweet is in for at least 10 examples each of e for English and n for non-English. There is a data/disney_e_n.csv file in the distribution; you can use this if you don't want to deal with annotating data. If you are not sure about a tweet, feel free to ignore it. Unannotated data is ignored. Have a look at the following screenshot:
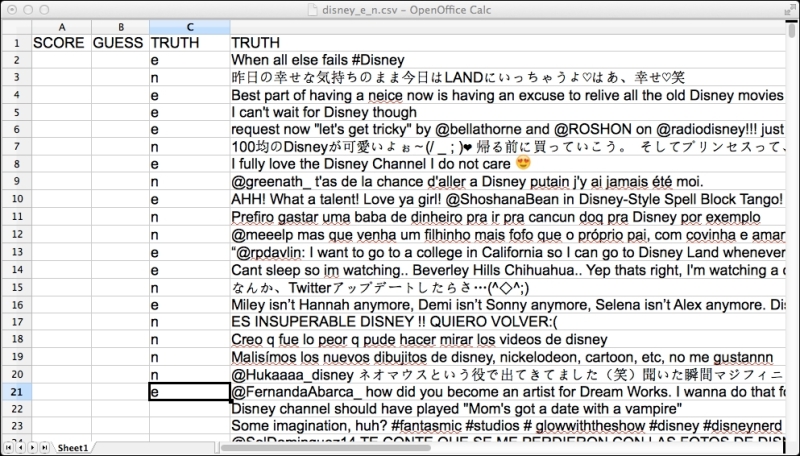
Screenshot of the spreadsheet with human annotations for English 'e' and non-English 'n'. It is known as truth data or gold standard data because it represents the phenomenon correctly.
Often, this data is called gold standard data, because it represents the truth. The "gold" in "gold standard" is quite literal. Back it up and store it with longevity in mind—it is most likely that it is the single-most valuable collection of bytes on your hard drive, because it is expensive to produce in any quantity and the cleanest articulation of what is being done. Implementations come and go; evaluation data lives on forever. The John Smith corpus from the The John Smith problem recipe, in Chapter 7, Finding Coreference Between Concepts/People, is the canonical evaluation corpus for that particular problem and lives on as the point of comparison for a line of research that started in 1997. The original implementation is long forgotten.
Perform the following steps to evaluate the classifiers:
Enter the following in the command prompt; this will run the default classifier on the texts in the default gold standard data. Then, it will compare the classifier's best category against what was annotated in the
TRUTHcolumn:java -cp lingpipe-cookbook.1.0.jar:lib/opencsv-2.4.jar:lib/lingpipe-4.1.0.jar com.lingpipe.cookbook.chapter1.RunConfusionMatrixThis class will then produce the confusion matrix:
reference\response \e,n, e 11,0, n 1,9,
The confusion matrix is aptly named since it confuses almost everyone initially, but it is, without a doubt, the best representation of classifier output, because it is very difficult to hide bad classifier performance with it. In other words, it is an excellent BS detector. It is the unambiguous view of what the classifier got right, what it got wrong, and what it thought was the right answer.
The sum of each row represents the items that are known by truth/reference/gold standard to belong to the category. For English (e) there were 11 tweets. Each column represents what the system thought was in the same labeled category. For English (e), the system thought 11 tweets were English and none were non-English (n). For the non-English category (n), there are 10 cases in truth, of which the classifier thought 1 was English (incorrectly) and 9 were non-English (correctly). Perfect system performance will have zeros in all the cells that are not located diagonally, from the top-left corner to the bottom-right corner.
The real reason it is called a confusion matrix is that it is relatively easy to see categories that the classifier is confusing. For example, British English and American English would likely be highly confusable. Also, confusion matrices scale to multiple categories quite nicely, as will be seen later. Visit the Javadoc for a more detailed explanation of the confusion matrix—it is well worth mastering.
Building on the code from the previous recipes in this chapter, we will focus on what is novel in the evaluation setup. The entirety of the code is in the distribution at src/com/lingpipe/cookbook/chapter1/RunConfusionMatrix.java. The start of main() is shown in the following code snippet. The code starts by reading from the arguments that look for non-default CSV data and serialized classifiers. Defaults, which this recipe uses, are shown here:
String inputPath = args.length > 0 ? args[0] : "data/disney_e_n.csv"; String classifierPath = args.length > 1 ? args[1] : "models/1LangId.LMClassifier";
Next, the language model and the .csv data will be loaded. The method differs slightly from the Util.CsvRemoveHeader explanation, in that it only accepts rows that have a value in the TRUTH column—see src/com/lingpipe/cookbook/Util.java if this is not clear:
@SuppressWarnings("unchecked")
BaseClassifier<CharSequence> classifier = (BaseClassifier<CharSequence>) AbstractExternalizable.readObject(new File(classifierPath));
List<String[]> rows = Util.readAnnotatedCsvRemoveHeader(new File(inputPath));Next, the categories will be found:
String[] categories = Util.getCategories(rows);
The method will accumulate all the category labels from the TRUTH column. The code is simple and is shown here:
public static String[] getCategories(List<String[]> data) {
Set<String> categories = new HashSet<String>();
for (String[] csvData : data) {
if (!csvData[ANNOTATION_OFFSET].equals("")) {
categories.add(csvData[ANNOTATION_OFFSET]);
}
}
return categories.toArray(new String[0]);
}The code will be useful when we run arbitrary data, where the labels are not known at compile time.
Then, we will set up BaseClassfierEvaluator. This requires the classifier to be evaluated. The categories and a boolean value that controls whether inputs are stored in the classifier for construction will also be set up:
boolean storeInputs = false; BaseClassifierEvaluator<CharSequence> evaluator = new BaseClassifierEvaluator<CharSequence>(classifier, categories, storeInputs);
Note that the classifier can be null and specified at a later time; the categories must exactly match those produced by the annotation and the classifier. We will not bother configuring the evaluator to store the inputs, because we are not going to use this capability in this recipe. See the Viewing error categories – false positives recipe for an example in which the inputs are stored and accessed.
Next, we will do the actual evaluation. The loop will iterate over each row of the information in the .csv file, build a Classified<CharSequence>, and pass it off to the evaluator's handle() method:
for (String[] row : rows) {
String truth = row[Util.ANNOTATION_OFFSET];
String text = row[Util.TEXT_OFFSET];
Classification classification = new Classification(truth);
Classified<CharSequence> classified = new Classified<CharSequence>(text,classification);
evaluator.handle(classified);
}The fourth line will create a classification object with the value from the truth annotation—e or n in this case. This is the same type as the one BaseClassifier<E> returns for the bestCategory() method. There is no special type for truth annotations. The next line adds in the text that the classification applies to and we get a Classified<CharSequence> object.
The last line of the loop will apply the handle method to the created classified object. The evaluator assumes that data supplied to its handle method is a truth annotation, which is handled by extracting the data being classified, applying the classifier to this data, getting the resulting firstBest() classification, and finally noting whether the classification matches that of what was just constructed with the truth. This happens for each row of the .csv file.
Outside the loop, we will print out the confusion matrix with Util.createConfusionMatrix():
System.out.println(Util.confusionMatrixToString(evaluator.confusionMatrix()));
Examining this code is left to the reader. That's it; we have evaluated our classifier and printed out the confusion matrix.