

Aggregate metrics such as mean, max, min, standard deviation, and so on, provide the basic overview of a dataset. You may perform these calculations, either for the whole dataset or to a subset or a sample of the dataset.
In this recipe, we will use Hadoop MapReduce to calculate the minimum, maximum, and average size of files served from a web server, by processing logs of the web server. The following figure shows the execution flow of this computation:
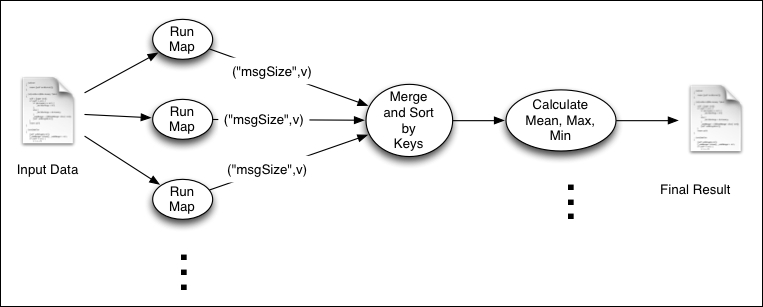
As shown in the figure, the Map function emits the size of the file as the value and the string msgSize as the key. We use a single Reduce task, and all the intermediate key-value pairs will be sent to that Reduce task. Then, the Reduce function calculates the aggregate values using the information emitted by the Map tasks.