

Like most functional languages, Scala provides developers and scientists with a toolbox to implement iterative computations that can be easily woven into a coherent dataflow. To some extent, Scala can be regarded as an extension of the popular MapReduce model for distributed computation of large amounts of data. Among the capabilities of the language, the following features are deemed essential in machine learning and statistical analysis.
Functors and monads are important concepts in functional programming. Monads are derived from the category and group theory that allow developers to create a high-level abstraction as illustrated in Scalaz, Twitter's Algebird, or Google's Breeze Scala libraries. More information about these libraries can be found at the following links:
In mathematics, a category M is a structure that is defined by:
Objects of some type: {x ϵ X, y ϵ Y, z ϵ Z, …}
Morphisms or maps applied to these objects: x ϵ X, y ϵ Y, f: x -› y
Composition of morphisms: f: x -› y, g: y -› z => g o f: x -› z
Covariant, contravariant functors, and bifunctors are well-understood concepts in algebraic topology that are related to manifold and vector bundles. They are commonly used in differential geometry and generation of non-linear models from data.
Scientists define observations as sets or vectors of features. Classification problems rely on the estimation of the similarity between vectors of observations. One technique consists of comparing two vectors by computing the normalized inner product. A co-vector is defined as a linear map α of a vector to the inner product (field).
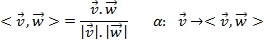
Let's define a vector as a constructor from any _ => Vector[_] field (or Function1[_, Vector]). A co-vector is then defined as the mapping function of a vector to its Vector[_] => _ field (or Function1[Vector, _]).
Let's define a two-dimensional (two types or fields) higher kind structure, Hom, that can be defined as either a vector or co-vector by fixing one of the two types:
type Hom[T] = { type Right[X] = Function1[X,T] // Co-vector type Left[X] = Function1[T,X] // Vector }
Note
Tensors and manifolds
Vectors and co-vectors are classes of tensor (contravariant and covariant). Tensors (fields) are used in manifold learning of nonlinear models and in the generation of kernel functions. Manifolds are briefly introduced in the Manifolds section under Dimension reduction in Chapter 4, Unsupervised Learning. The topic of tensor fields and manifold learning is beyond the scope of this book.
The projections of the higher kind, Hom, to the Right or Left single parameter types are known as functors, which are as follows:
A covariant functor for the
rightprojectionA contravariant functor for the
leftprojection.
A covariant functor of a variable is a map F: C => C such that:
If f: x -› y is a morphism on C, then F(x) -› F(y) is also a morphism on C
If id: x -› x is the identity morphism on C, then F(id) is also an identity morphism on C
If g: y -› z is also a morphism on C, then F(g o f) = F(g) o F(f)
The definition of the F[U => V] := F[U] => F[V]covariant functor in Scala is as follows:
trait Functor[M[_]] { def map[U,V](m: M[U])(f: U =>V): M[V] }
For example, let's consider an observation defined as a n dimension vector of a T type, Obs[T]. The constructor for the observation can be represented as Function1[T,Obs]. Its ObsFunctor functor is implemented as follows:
trait ObsFunctor[T] extends Functor[(Hom[T])#Left] { self => override def map[U,V](vu: Function1[T,U])(f: U =>V): Function1[T,V] = f.compose(vu) }
The functor is qualified as a covariant functor because the morphism is applied to the return type of the element of Obs as Function1[T, Obs]. The Hom projection of the two parameters types to a vector is implemented as (Hom[T])#Left.
A contravariant functor of one variable is a map F: C => C such that:
If f: x -› y is a morphism on C, then F(y) -> F(x) is also a morphism on C
If id: x -› x is the identity morphism on C, then F(id) is also an identity morphism on C
If g: y -› z is also a morphism on C, then F(g o f) = F(f) o F(g)
The definition of the F[U => V] := F[V] => F[U] contravariant functor in Scala is as follows:
trait CoFunctor[M[_]] { def map[U,V](m: M[U])(f: V =>U): M[V] }
Note that the input and output types in the f morphism are reversed from the definition of a covariant functor. The constructor for the co-vector can be represented as Function1[Obs,T]. Its CoObsFunctor functor is implemented as follows:
trait CoObsFunctor[T] extends CoFunctor[(Hom[T])#Right] { self => override def map[U,V](vu: Function1[U,T])(f: V =>U): Function1[V,T] = f.andThen(vu) }
Monads are structures in algebraic topology that are related to the category theory. Monads extend the concept of a functor to allow a composition known as the monadic composition
of morphisms on a single type. They enable the chaining or weaving of computation into a sequence of steps or pipeline. The collections bundled with the Scala standard library (List, Map, and so on) are constructed as monads [1:1].
Monads provide the ability for those collections to perform the following functions:
Create the collection
Transform the elements of the collection
Flatten nested collections
An example is as follows:
trait Monad[M[_]] {
def unit[T](a: T): M[T]
def map[U,V](m: M[U])(f U =>V): M[V]
def flatMap[U,V](m: M[U])(f: U =>M[V]): M[V]
}Monads are therefore critical in machine learning as they enable you to compose multiple data transformation functions into a sequence or workflow. This property is applicable to any type of complex scientific computation [1:2].
Note
The monadic composition of kernel functions
Monads are used in the composition of kernel functions in the Kernel monadic composition section under Kernel functions section in Chapter 8, Kernel Models and Support Vector Machines.
As seen previously, functors and monads enable parallelization and chaining of data processing functions by leveraging the Scala higher-order methods. In terms of implementation, actors are one of the core elements that make Scala scalable. Actors provide Scala developers with a high level of abstraction to build scalable, distributed, and concurrent applications. Actors hide the nitty-gritty implementation details of concurrency and the management of the underlying threads pool. Actors communicate through asynchronous immutable messages. A distributed computing Scala framework such as Akka or Apache Spark extends the capabilities of the Scala standard library to support computation on very large datasets. Akka and Apache Spark are described in detail in the last chapter of this book [1:3].
In a nutshell, a workflow is implemented as a sequence of activities or computational tasks. These tasks consist of high-order Scala methods such as flatMap, map, fold, reduce, collect, join, or filter that are applied to a large collection of observations. Scala provides developers with the tools to partition datasets and execute the tasks through a cluster of actors. Scala also supports message dispatching and routing between local and remote actors. A developer can decide to deploy a workflow either locally or across multiple CPU cores and servers with very few code alterations.
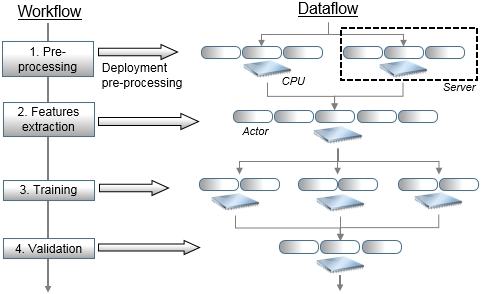
Deployment of a workflow for model training as a distributed computation
In the preceding diagram, a controller, that is, the master node, manages the sequence of tasks 1 to 4 similar to a scheduler. These tasks are actually executed over multiple worker nodes, which are implemented by actors. The master node or actor exchanges messages with the workers to manage the state of the execution of the workflow as well as its reliability, as illustrated in the Scalability with Actors section in Chapter 12, Scalable Frameworks. High availability of these tasks is implemented through a hierarchy of supervising actors.
Scala supports dependency injection using a combination of abstract variables, self-referenced composition, and stackable traits. One of the most commonly used dependency injection patterns, the cake pattern, is described in the Composing mixins to build a workflow section in Chapter 2, Hello World!
Scala embeds Domain Specific Languages (DSL) natively. DSLs are syntactic layers built on top of Scala native libraries. DSLs allow software developers to abstract computation in terms that are easily understood by scientists. The most notorious application of DSLs is the definition of the emulation of the syntax used in the MATLAB program, which data scientists are familiar with.