





Machine learning has been around for at least 60 years. Growing out of the quest for artificial intelligence, early machine learning systems used hand-coded rules of if...else statements to process data and make decisions. Think of a spam filter whose job is to parse incoming emails and move unwanted messages to a spam folder:

We could come up with a blacklist of words that, whenever they show up in a message, would mark an email as spam. This is a simple example of a hand-coded expert system. (We will build a smarter one in Chapter 7, Implementing a Spam Filter with Bayesian Learning.)
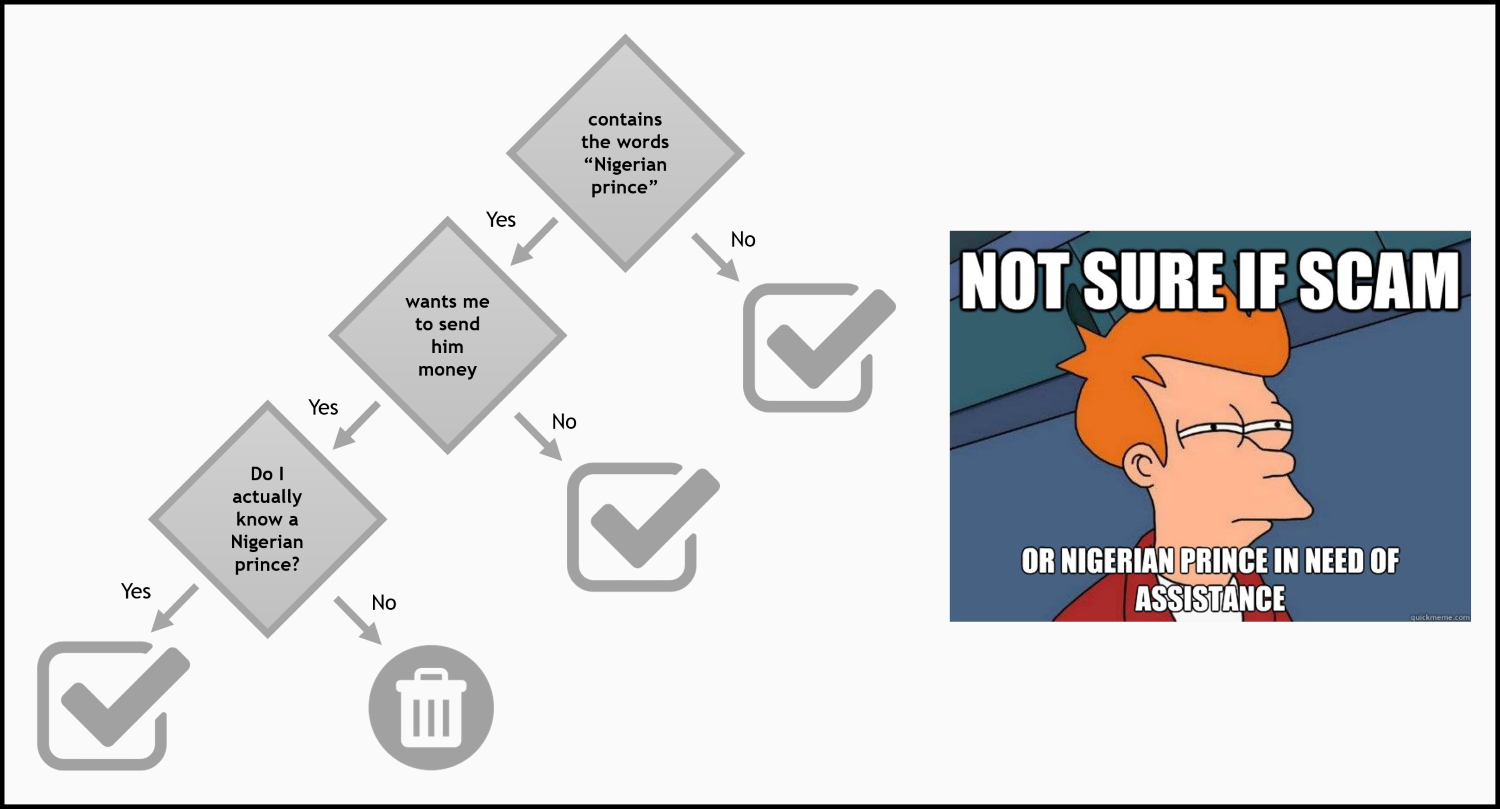
We can think of these expert decision rules to become arbitrarily complicated if we are allowed to combine and nest them in what is known as a decision tree (Chapter 5, Using Decision Trees to Make a Medical Diagnosis). Then, it becomes possible to make more informed decisions that involve a series of decision steps, as shown in the following image:
Hand-coding these decision rules is sometimes feasible, but has two major disadvantages:
- The logic required to make a decision applies only to a specific task in a single domain. For example, there is no way that we could use this spam filter to tag our friends in a picture. Even if we wanted to change the spam filter to do something slightly different, such as filtering out phishing emails in general, we would have to redesign all the decision rules.
- Designing rules by hand requires a deep understanding of the problem. We would have to know exactly which type of emails constitute spam, including all possible exceptions. This is not as easy as it seems; otherwise, we wouldn't often be double-checking our spam folder for important messages that might have been accidentally filtered out. For other domain problems, it is simply not possible to design the rules by hand.
This is where machine learning comes in. Sometimes, tasks cannot be defined well--except maybe by example--and we would like machines to make sense of and solve the tasks by themselves. Other times, it is possible that, hidden among large piles of data, are important relationships and correlations that we as humans might have missed (see Chapter 8, Discovering Hidden Structures with Unsupervised Learning). In these cases, machine learning can often be used to extract these hidden relationships (also known as data mining).
A good example of where man-made expert systems have failed is in detecting faces in images. Silly, isn't it? Today, every smart phone can detect a face in an image. However, 20 years ago, this problem was largely unsolved. The reason for this was the way humans think about what constitutes a face was not very helpful to machines. As humans, we tend not to think in pixels. If we were asked to detect a face, we would probably just look for the defining features of a face, such as eyes, nose, mouth, and so on. But how would we tell a machine what to look for, when all the machine knows is that images have pixels and pixels have a certain shade of gray? For the longest time, this difference in image representation basically made it impossible for a human to come up with a good set of decision rules that would allow a machine to detect a face in an image. We will talk about different approaches to this problem in Chapter 4, Representing Data and Engineering Features.
However, with the advent of convolutional neural networks and deep learning (Chapter 9, Using Deep Learning to Classify Handwritten Digits), machines have become as successful as us when it comes to recognizing faces. All we had to do was simply present a large collection of images of faces to the machine. From there on, the machine was able to discover the set of characteristics that would allow it to identify a face, without having to approach the problem in the same way as we would do. This is the true power of machine learning.







