

Sometimes each sample, or in other words, each row of the predictor variable matrix, is treated with different weightage. Normally, weights are given by a diagonal matrix where each element on the diagonal represent the weight for the row. If the weight is represented by W, then theta (or the linear regression coefficient) is given by the following formula:
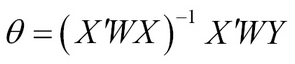
Math.NET has a special class called WeightedRegression to find theta. If all the elements of the weight matrix are 1 then we have the same linear regression model as before.
The weight matrix is normally determined by taking a look at the new value for which the target variable has to be evaluated. If the new value is depicted as x, then the weights are normally calculated using the following formula:
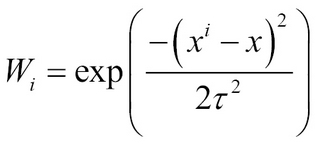
The numerator of the weight matrix can be calculated as the Euclidean distance between two vectors. The first vector is from the training data and the other is the new vector depicting the new entry for which the...