

Data in HDFS may not always be placed uniformly. There can be numerous reasons for this. One of the major reasons is the addition of new nodes to the cluster. In such a case, it's the Hadoop administrator's job to make sure that they execute the balancer command to rebalance the data load.
In the previous recipe, we added a new node to the cluster while the other three nodes were already part of the cluster. When you execute the dfsadmin report command, you would have noticed that the data is not uniformly balanced because of the addition of a new node. In my case, here is the state of the new node versus the old node.
This is the code for the old node:
Name: 172.31.0.9:50010 (ip-172-31-0-9.us-west-2.compute.internal) Hostname: ip-172-31-0-9.us-west-2.compute.internal Decommission Status : Normal Configured Capacity: 8309932032 (7.74 GB) DFS Used: 67551232 (64.42 MB) Non DFS Used: 2193256448 (2.04 GB) DFS Remaining: 6049124352 (5.63 GB) DFS Used%: 0.81% DFS Remaining%: 72.79% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Oct 08 08:57:23 UTC 2015
This is the code for the new node:
Name: 172.31.18.55:50010 (ip-172-31-18-55.us-west-2.compute.internal) Hostname: ip-172-31-18-55.us-west-2.compute.internal Decommission Status : Normal Configured Capacity: 8309932032 (7.74 GB) DFS Used: 1127585 (1.08 MB) Non DFS Used: 2372033375 (2.21 GB) DFS Remaining: 5936771072 (5.53 GB) DFS Used%: 0.01% DFS Remaining%: 71.44% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Oct 08 08:57:25 UTC 2015
This means that the load on the cluster is not uniform. In this case, we can execute the balancer command to distribute the data uniformly throughout the data nodes:
hdfs balancer
This will initiate the block balancing activity across the cluster. By default, it will run the balancing activity to make sure that the block storage in the nodes does not differ by more than 10%. You can also decide on the threshold limit by setting an optional parameter called threshold:
hdfs balancer -threshold 5
This will execute the balancer command with 5% threshold. This is how the sample execution looks:
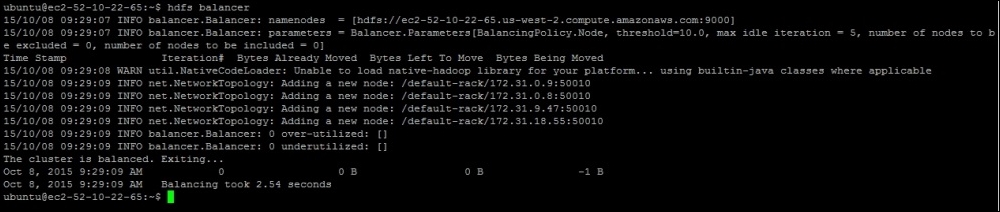
The balancer command provides instructions to namenode so that it can rebalance the data uniformly across datanode. This balancing is done by repositioning the blocks placed in datanode. So, if a data node is over utilized, some the blocks from that node would be repositioned to the node that is underutilized.
There are some options you can provide as arguments to this command:
Usage: hdfs balancer [-policy <policy>] the balancing policy: datanode or blockpool [-threshold <threshold>] Percentage of disk capacity [-exclude [-f <hosts-file> | <comma-separated list of hosts>]] Excludes the specified datanodes. [-include [-f <hosts-file> | <comma-separated list of hosts>]] Includes only the specified datanodes. [-idleiterations <idleiterations>] Number of consecutive idle iterations (-1 for Infinite) before exit.