

One of the main problems of linear regression is that it's sensitive to outliers. During data collection in the real world, it's quite common to wrongly measure the output. Linear regression uses ordinary least squares, which tries to minimize the squares of errors. The outliers tend to cause problems because they contribute a lot to the overall error. This tends to disrupt the entire model.
Let's consider the following figure:
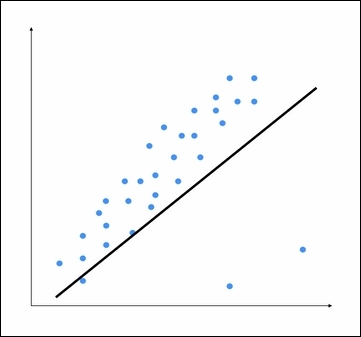
The two points on the bottom are clearly outliers, but this model is trying to fit all the points. Hence, the overall model tends to be inaccurate. By visual inspection, we can see that the following figure is a better model:
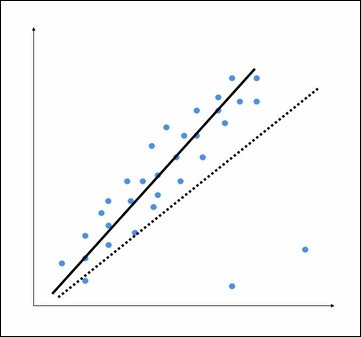
Ordinary least squares considers every single datapoint when it's building the model. Hence, the actual model ends up looking like the dotted line as shown in the preceding figure. We can clearly see that this model is suboptimal. To avoid this, we use regularization where a penalty is imposed on the size of the coefficients. This method is called Ridge Regression.
Let's see how to build a ridge regressor in Python:
You can load the data from the
data_multi_variable.txtfile. This file contains multiple values in each line. All the values except the last value form the input feature vector.Add the following lines to
regressor.py. Let's initialize a ridge regressor with some parameters:ridge_regressor = linear_model.Ridge(alpha=0.01, fit_intercept=True, max_iter=10000)
The
alphaparameter controls the complexity. Asalphagets closer to0, the ridge regressor tends to become more like a linear regressor with ordinary least squares. So, if you want to make it robust against outliers, you need to assign a higher value toalpha. We considered a value of0.01, which is moderate.Let's train this regressor, as follows:
ridge_regressor.fit(X_train, y_train) y_test_pred_ridge = ridge_regressor.predict(X_test) print "Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred_ridge), 2) print "Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred_ridge), 2) print "Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred_ridge), 2) print "Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred_ridge), 2) print "R2 score =", round(sm.r2_score(y_test, y_test_pred_ridge), 2)
Run this code to view the error metrics. You can build a linear regressor to compare and contrast the results on the same data to see the effect of introducing regularization into the model.