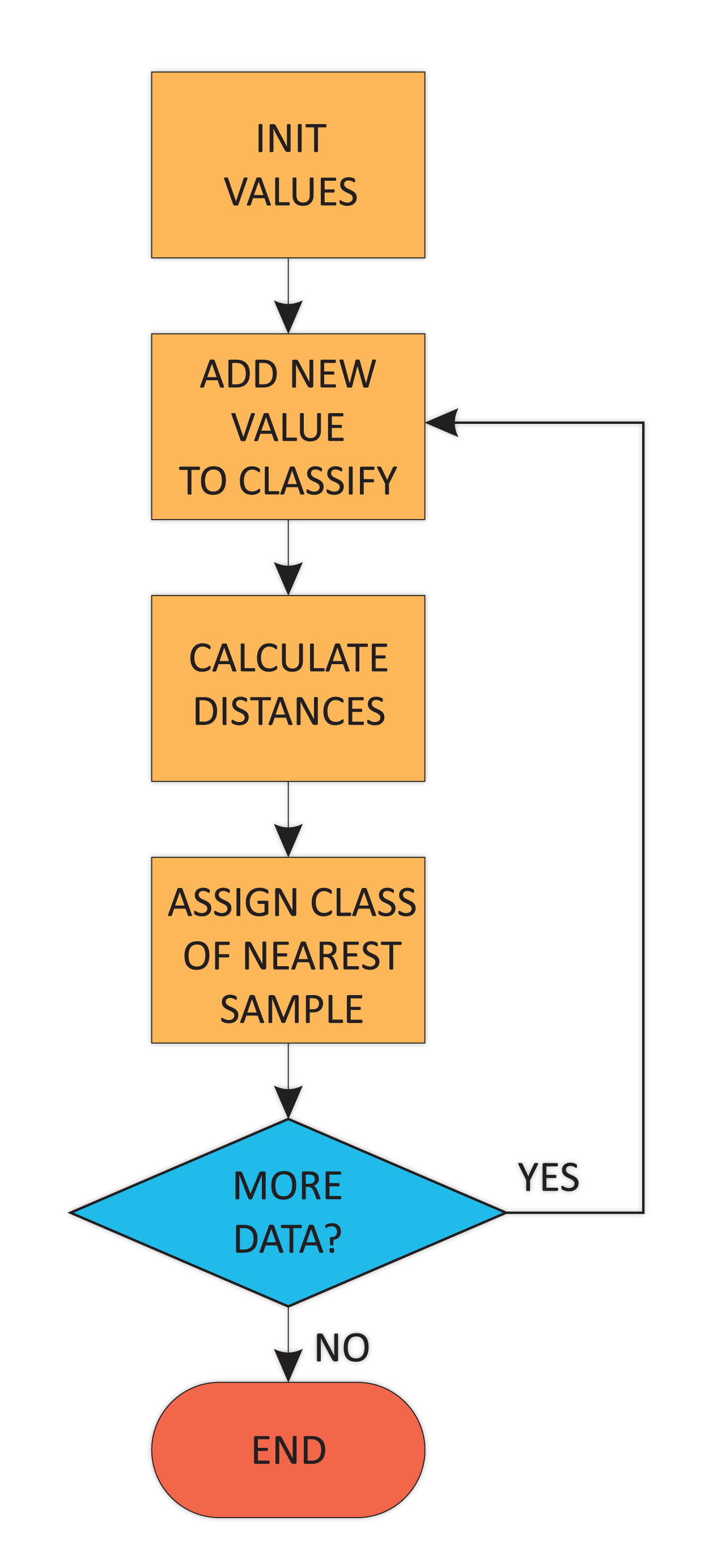
K-NN is another classical method of clustering. It builds groups of samples, supposing that each new sample will have the same class as its neighbors, without looking for a global representative central sample. Instead, it looks at the environment, looking for the most frequent class on each new sample's environment.
-
Book Overview & Buying

-
Table Of Contents

Machine Learning for Developers
By :
Machine Learning for Developers
By:
Overview of this book
Most of us have heard about the term Machine Learning, but surprisingly the question frequently asked by developers across the globe is, “How do I get started in Machine Learning?”. One reason could be attributed to the vastness of the subject area because people often get overwhelmed by the abstractness of ML and terms such as regression, supervised learning, probability density function, and so on. This book is a systematic guide teaching you how to implement various Machine Learning techniques and their day-to-day application and development.
You will start with the very basics of data and mathematical models in easy-to-follow language that you are familiar with; you will feel at home while implementing the examples. The book will introduce you to various libraries and frameworks used in the world of Machine Learning, and then, without wasting any time, you will get to the point and implement Regression, Clustering, classification, Neural networks, and more with fun examples. As you get to grips with the techniques, you’ll learn to implement those concepts to solve real-world scenarios for ML applications such as image analysis, Natural Language processing, and anomaly detections of time series data.
By the end of the book, you will have learned various ML techniques to develop more efficient and intelligent applications.
Table of Contents (10 chapters)
Preface
 Free Chapter
Free Chapter
Introduction - Machine Learning and Statistical Science
The Learning Process
Clustering
Linear and Logistic Regression
Neural Networks
Convolutional Neural Networks
Recurrent Neural Networks
Recent Models and Developments
Software Installation and Configuration