

In this recipe we will install Requests and Beautiful Soup and scrape some content from www.python.org. We'll install both of the libraries and get some basic familiarity with them. We'll come back to them both in subsequent chapters and dive deeper into each.
Scraping Python.org with Requests and Beautiful Soup
Getting ready...
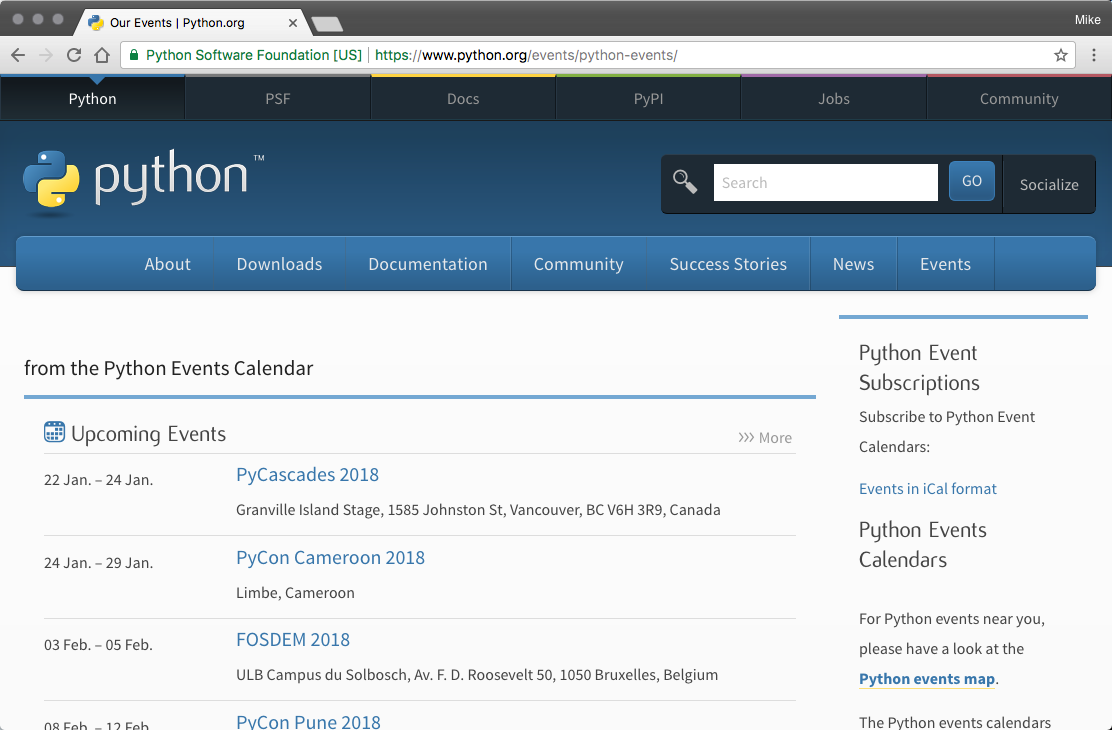
In this recipe, we will scrape the upcoming Python events from https://www.python.org/events/pythonevents. The following is an an example of The Python.org Events Page (it changes frequently, so your experience will differ):
We will need to ensure that Requests and Beautiful Soup are installed. We can do that with the following:
pywscb $ pip install requests
Downloading/unpacking requests
Downloading requests-2.18.4-py2.py3-none-any.whl (88kB): 88kB downloaded
Downloading/unpacking certifi>=2017.4.17 (from requests)
Downloading certifi-2018.1.18-py2.py3-none-any.whl (151kB): 151kB downloaded
Downloading/unpacking idna>=2.5,<2.7 (from requests)
Downloading idna-2.6-py2.py3-none-any.whl (56kB): 56kB downloaded
Downloading/unpacking chardet>=3.0.2,<3.1.0 (from requests)
Downloading chardet-3.0.4-py2.py3-none-any.whl (133kB): 133kB downloaded
Downloading/unpacking urllib3>=1.21.1,<1.23 (from requests)
Downloading urllib3-1.22-py2.py3-none-any.whl (132kB): 132kB downloaded
Installing collected packages: requests, certifi, idna, chardet, urllib3
Successfully installed requests certifi idna chardet urllib3
Cleaning up...
pywscb $ pip install bs4
Downloading/unpacking bs4
Downloading bs4-0.0.1.tar.gz
Running setup.py (path:/Users/michaelheydt/pywscb/env/build/bs4/setup.py) egg_info for package bs4
How to do it...
Now let's go and learn to scrape a couple events. For this recipe we will start by using interactive python.
-
Start it with the ipython command:
$ ipython
Python 3.6.1 |Anaconda custom (x86_64)| (default, Mar 22 2017, 19:25:17)
Type "copyright", "credits" or "license" for more information.
IPython 5.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]:
- Next we import Requests
In [1]: import requests
- We now use requests to make a GET HTTP request for the following url: https://www.python.org/events/python-events/ by making a GET request:
In [2]: url = 'https://www.python.org/events/python-events/'
In [3]: req = requests.get(url)
- That downloaded the page content but it is stored in our requests object req. We can retrieve the content using the .text property. This prints the first 200 characters.
req.text[:200]
Out[4]: '<!doctype html>\n<!--[if lt IE 7]> <html class="no-js ie6 lt-ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 7]> <html class="no-js ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 8]> <h'
We now have the raw HTML of the page. We can now use beautiful soup to parse the HTML and retrieve the event data.
- First import Beautiful Soup
In [5]: from bs4 import BeautifulSoup
- Now we create a BeautifulSoup object and pass it the HTML.
In [6]: soup = BeautifulSoup(req.text, 'lxml')
- Now we tell Beautiful Soup to find the main <ul> tag for the recent events, and then to get all the <li> tags below it.
In [7]: events = soup.find('ul', {'class': 'list-recent-events'}).findAll('li')
- And finally we can loop through each of the <li> elements, extracting the event details, and print each to the console:
In [13]: for event in events:
...: event_details = dict()
...: event_details['name'] = event_details['name'] = event.find('h3').find("a").text
...: event_details['location'] = event.find('span', {'class', 'event-location'}).text
...: event_details['time'] = event.find('time').text
...: print(event_details)
...:
{'name': 'PyCascades 2018', 'location': 'Granville Island Stage, 1585 Johnston St, Vancouver, BC V6H 3R9, Canada', 'time': '22 Jan. – 24 Jan. 2018'}
{'name': 'PyCon Cameroon 2018', 'location': 'Limbe, Cameroon', 'time': '24 Jan. – 29 Jan. 2018'}
{'name': 'FOSDEM 2018', 'location': 'ULB Campus du Solbosch, Av. F. D. Roosevelt 50, 1050 Bruxelles, Belgium', 'time': '03 Feb. – 05 Feb. 2018'}
{'name': 'PyCon Pune 2018', 'location': 'Pune, India', 'time': '08 Feb. – 12 Feb. 2018'}
{'name': 'PyCon Colombia 2018', 'location': 'Medellin, Colombia', 'time': '09 Feb. – 12 Feb. 2018'}
{'name': 'PyTennessee 2018', 'location': 'Nashville, TN, USA', 'time': '10 Feb. – 12 Feb. 2018'}
This entire example is available in the 01/01_events_with_requests.py script file. The following is its content and it pulls together all of what we just did step by step:
import requests
from bs4 import BeautifulSoup
def get_upcoming_events(url):
req = requests.get(url)
soup = BeautifulSoup(req.text, 'lxml')
events = soup.find('ul', {'class': 'list-recent-events'}).findAll('li')
for event in events:
event_details = dict()
event_details['name'] = event.find('h3').find("a").text
event_details['location'] = event.find('span', {'class', 'event-location'}).text
event_details['time'] = event.find('time').text
print(event_details)
get_upcoming_events('https://www.python.org/events/python-events/')
You can run this using the following command from the terminal:
$ python 01_events_with_requests.py
{'name': 'PyCascades 2018', 'location': 'Granville Island Stage, 1585 Johnston St, Vancouver, BC V6H 3R9, Canada', 'time': '22 Jan. – 24 Jan. 2018'}
{'name': 'PyCon Cameroon 2018', 'location': 'Limbe, Cameroon', 'time': '24 Jan. – 29 Jan. 2018'}
{'name': 'FOSDEM 2018', 'location': 'ULB Campus du Solbosch, Av. F. D. Roosevelt 50, 1050 Bruxelles, Belgium', 'time': '03 Feb. – 05 Feb. 2018'}
{'name': 'PyCon Pune 2018', 'location': 'Pune, India', 'time': '08 Feb. – 12 Feb. 2018'}
{'name': 'PyCon Colombia 2018', 'location': 'Medellin, Colombia', 'time': '09 Feb. – 12 Feb. 2018'}
{'name': 'PyTennessee 2018', 'location': 'Nashville, TN, USA', 'time': '10 Feb. – 12 Feb. 2018'}
How it works...
We will dive into details of both Requests and Beautiful Soup in the next chapter, but for now let's just summarize a few key points about how this works. The following important points about Requests:
- Requests is used to execute HTTP requests. We used it to make a GET verb request of the URL for the events page.
- The Requests object holds the results of the request. This is not only the page content, but also many other items about the result such as HTTP status codes and headers.
- Requests is used only to get the page, it does not do an parsing.
We use Beautiful Soup to do the parsing of the HTML and also the finding of content within the HTML.
To understand how this worked, the content of the page has the following HTML to start the Upcoming Events section:
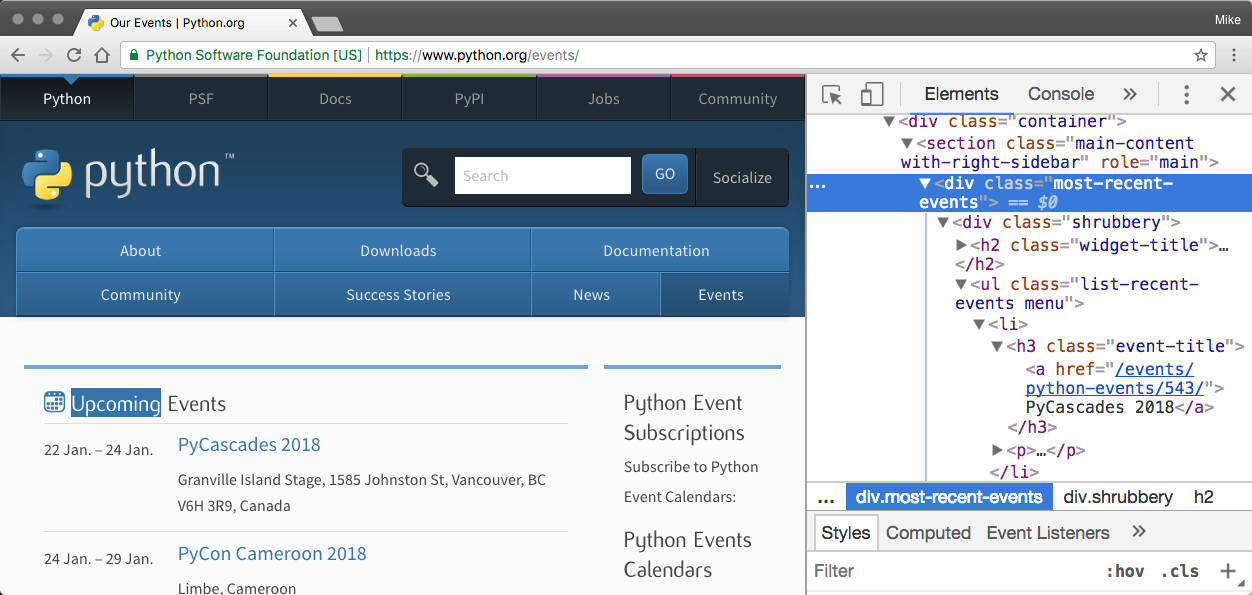
We used the power of Beautiful Soup to:
- Find the <ul> element representing the section, which is found by looking for a <ul> with the a class attribute that has a value of list-recent-events.
- From that object, we find all the <li> elements.
Each of these <li> tags represent a different event. We iterate over each of those making a dictionary from the event data found in child HTML tags:
- The name is extracted from the <a> tag that is a child of the <h3> tag
- The location is the text content of the <span> with a class of event-location
- And the time is extracted from the datetime attribute of the <time> tag.