Users can sign up for Google Cloud using their google account or Gmail ID. Google offers a free trial for most of its cloud services for up to 1 year. If you sign up using your company's account, Google will create an organization and will add users from the same domain to the organization so that resources can be shared with your team. You can also use your personal Gmail to sign up as an individual user to try the services.
After the successful sign up for Google Cloud, a new project with the default name My First Project is created by Google. We can use this project as a demo in this chapter. The next and most important step is to set up a budget alert for this project as well as all future projects that will be created on the Google Cloud platform. This will help the user to keep track of the budget and monitor any sudden surge in billing.
- Click on the sandwich button on the top left to open the left-hand-side navigation menu.
- Click on Billing in the left-hand-side menu and the billing dashboard will be displayed with the current billing details:
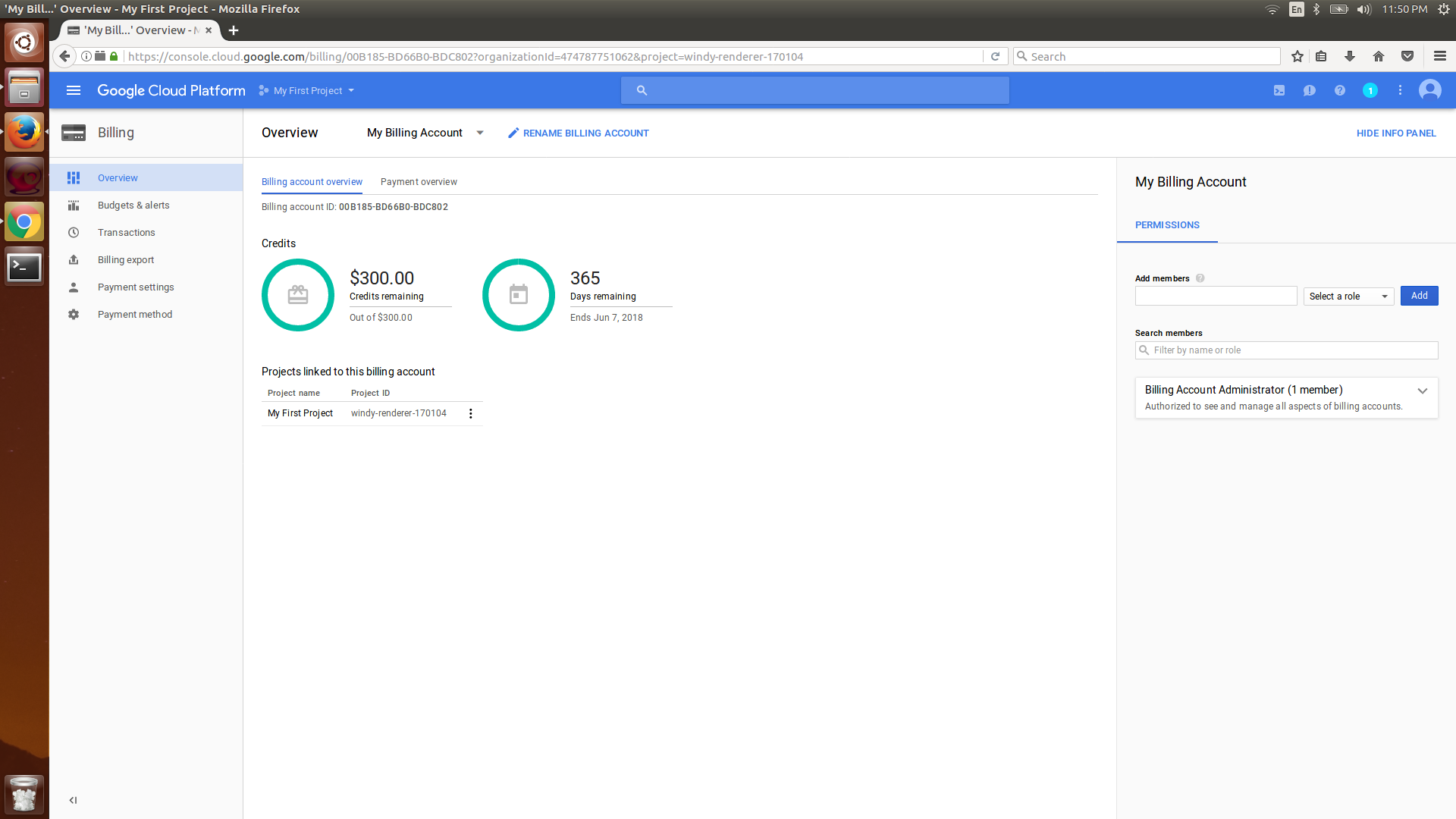
- Click on Budgets & alerts and create a budget at the billing account level so that your total expenses across all projects don't exceed the limit.
- Choose My Billing account in the Project or billing account dropdown and check the Include credit as a budget expense option. These budgets are monthly budgets. The user will receive an email if any of the budget exceeds the limit within that month.
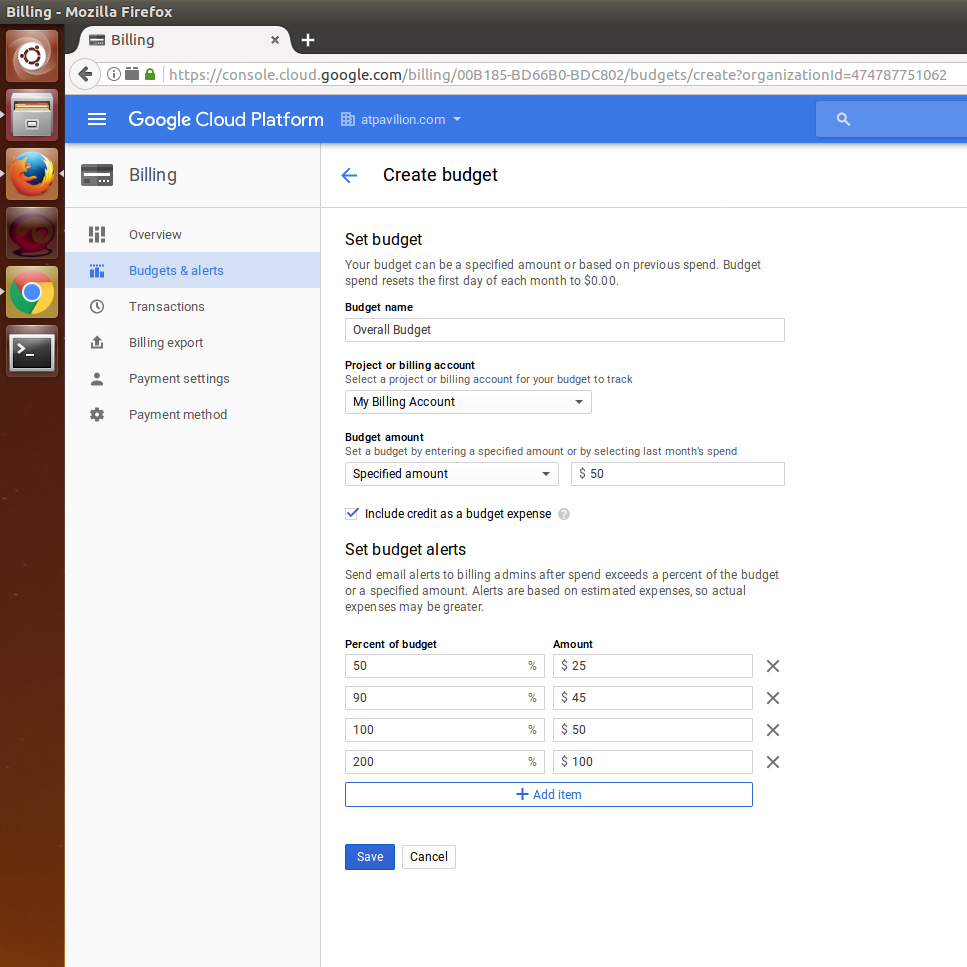
- Now, create a project-level budget alert by clicking on Budgets & alerts in the left-hand-side menu; this time, choose the project that was created by Google Cloud in the Project or billing account dropdown and check Include credit as budget expense:
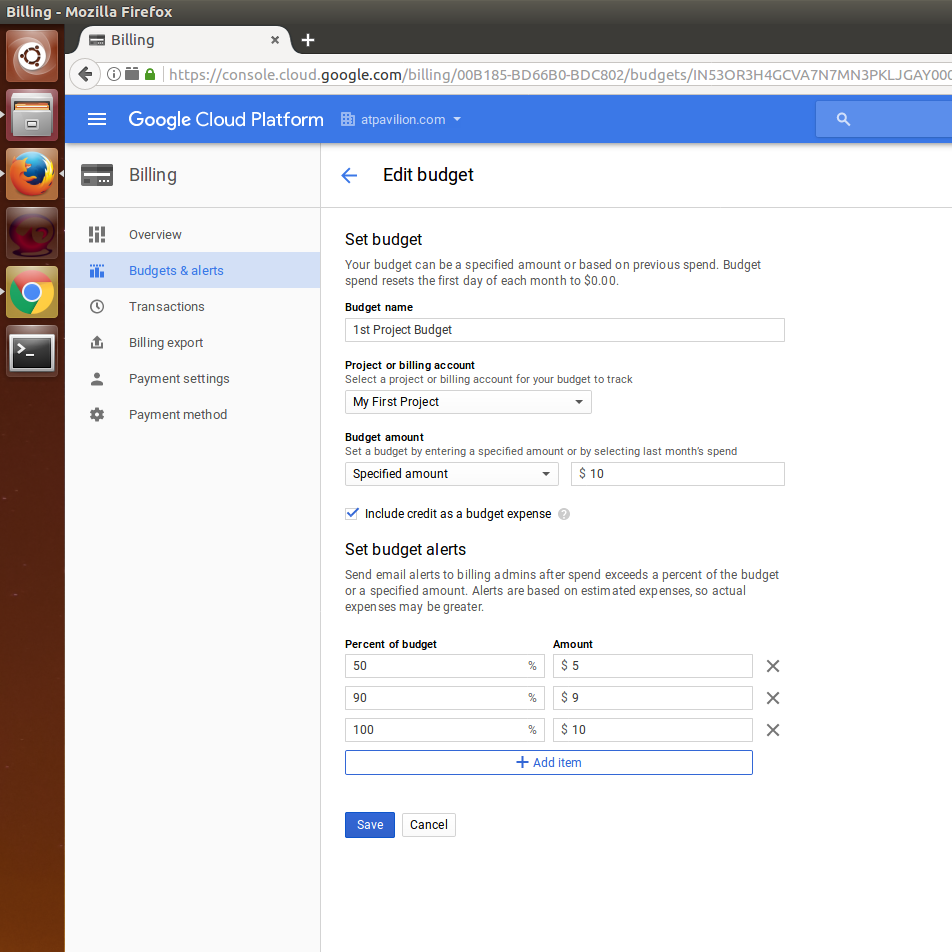
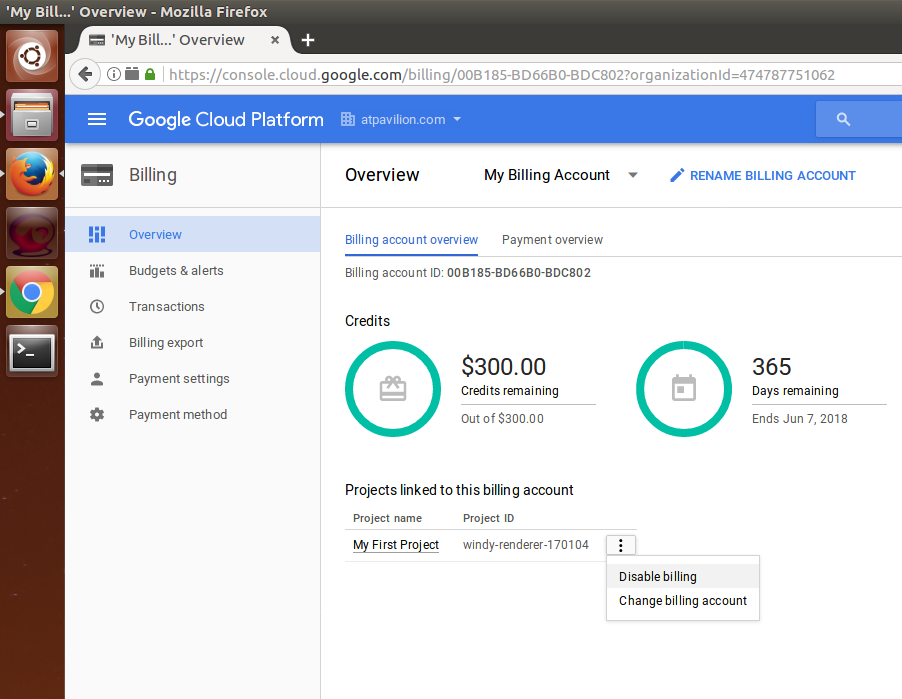
Whenever a project needs a service on the Google Cloud Platform, check out the following details about the service before deciding whether to purchase it:
- Quotas: Understand the quotas allocated to various services. Some quota restrictions will be waived based on the billing tier and additional pricing. Some services include free tier pricing.
- Sub-hour billing: Some services charge customers only for the minutes in which the resources are used and not for entire hours. It is better to understand whether the service you are planning to use is providing sub-hour billing. If it does not provide sub-hour billing, then plan to use the resources in one batch for a few hours rather than using them for a few minutes every hour.
- Sustained-use discount: If a service is being used for more than x number of hours in a month, Google may offer a sustained-use discount. Compute engine VMs and cloud SQL VMs are offered at up to 30% discount for sustained use. The more predictably you use the resources on Google Cloud, the more the discounts you get.
- Pre-emptible VMs: Pre-emptible VMs provide more savings than regular Compute engine VMs. These are short-lived VMs that can be created on the fly to deploy apps and run them. The catch is that these pre-emptible VMs can be reclaimed by Compute Engine anytime and your application will be provided 30 seconds to shut down. Turn off the VMs as soon as the process finishes.

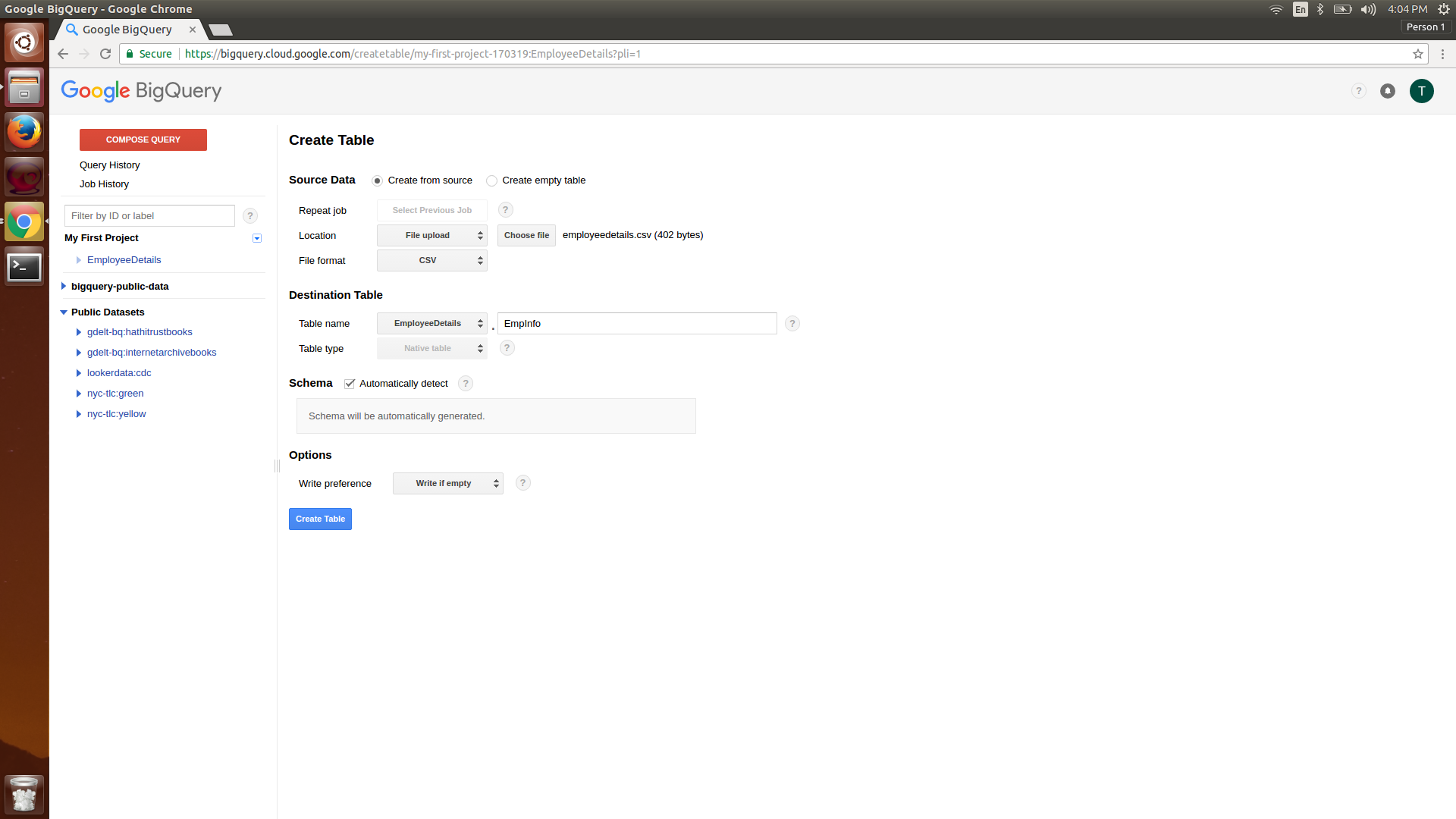
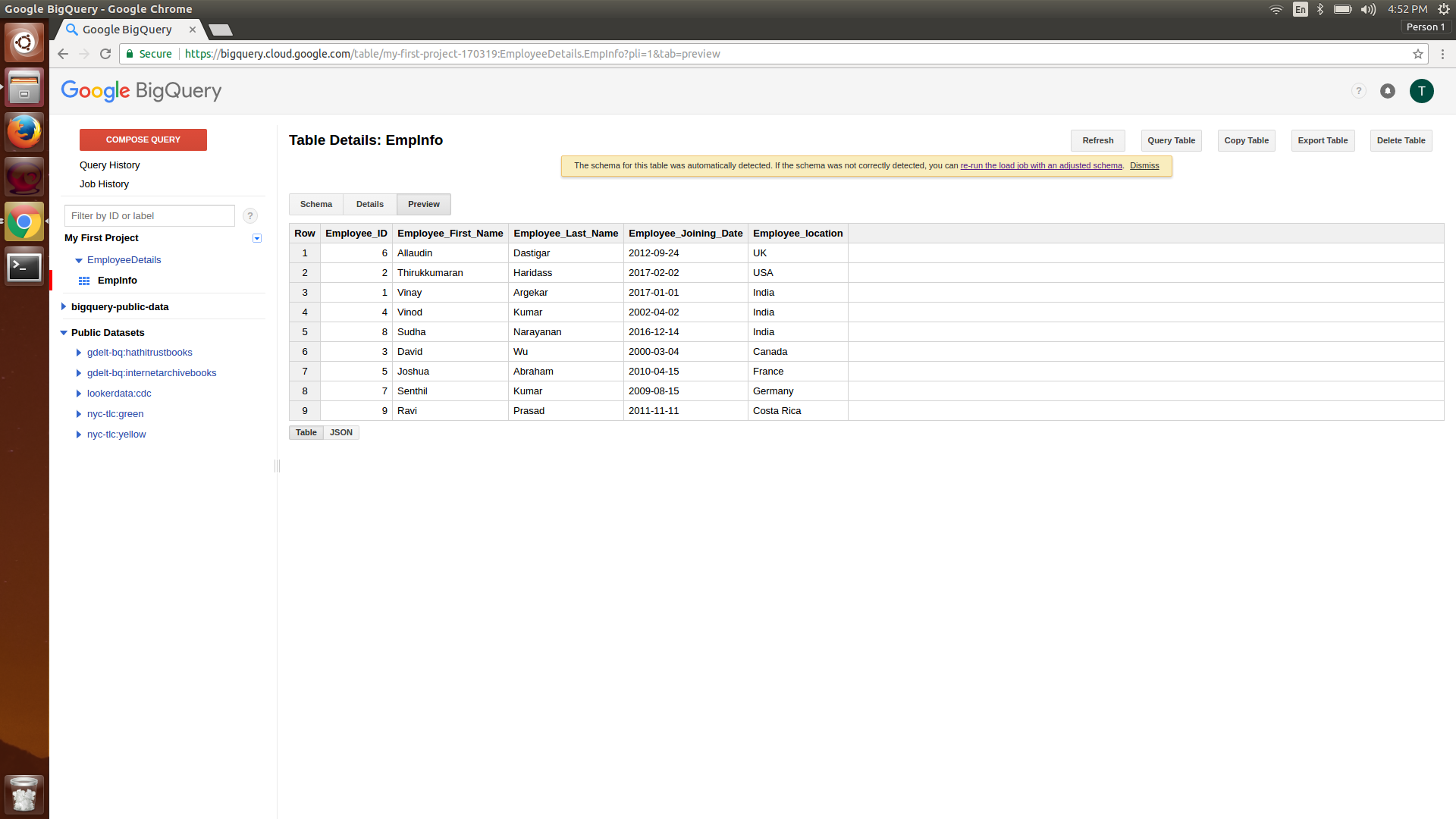



 icon at the top. Cloud Shell is a Linux VM that is created on the fly and has Google Cloud SDK installed with the default configuration.
icon at the top. Cloud Shell is a Linux VM that is created on the fly and has Google Cloud SDK installed with the default configuration.