The first thing to have is a function to create minibatches of training data. In fact, at each training iteration, we'd need to insert a minibatch of samples extracted from the training set. Here, we'll build a function that takes the observations, labels, and batch size as arguments and returns a minibatch generator. Furthermore, to introduce some variability in the training data, let's add another argument to the function, the possibility to shuffle the data to have different minibatches of data for each generator. Having different minibatches of data in each generator will force the model to learn the in-out connection and not memorize the sequence:
def minibatcher(X, y, batch_size, shuffle):
assert X.shape[0] == y.shape[0]
n_samples = X.shape[0]
if shuffle:
idx = np.random.permutation(n_samples)
else:
idx = list(range(n_samples))
for k in range(int(np.ceil(n_samples/batch_size))):
from_idx = k*batch_size
to_idx = (k+1)*batch_size
yield X[idx[from_idx:to_idx], :, :, :], y[idx[from_idx:to_idx], :]
To test this function, let's print the shapes of minibatches while imposing batch_size=10000:
for mb in minibatcher(X_train, y_train, 10000, True):
print(mb[0].shape, mb[1].shape)
That prints the following:
(10000, 32, 32, 1) (10000, 43)
(10000, 32, 32, 1) (10000, 43)
(9406, 32, 32, 1) (9406, 43)
Unsurprisingly, the 29,406 samples in the training set are split into two minibatches of 10,000 elements, with the last one of 9406 elements. Of course, there are the same number of elements in the label matrix too.
It's now time to build the model, finally! Let's first build the blocks that will compose the network. We can start creating the fully connected layer with a variable number of units (it's an argument), without activation. We've decided to use Xavier initialization for the coefficients (weights) and 0-initialization for the biases to have the layer centered and scaled properly. The output is simply the multiplication of the input tensor by the weights, plus the bias. Please take a look at the dimensionality of the weights, which is defined dynamically, and therefore can be used anywhere in the network:
import tensorflow as tf
def fc_no_activation_layer(in_tensors, n_units):
w = tf.get_variable('fc_W',
[in_tensors.get_shape()[1], n_units],
tf.float32,
tf.contrib.layers.xavier_initializer())
b = tf.get_variable('fc_B',
[n_units, ],
tf.float32,
tf.constant_initializer(0.0))
return tf.matmul(in_tensors, w) + b
Let's now create the fully connected layer with activation; specifically, here we will use the leaky ReLU. As you can see, we can build this function using the previous one:
def fc_layer(in_tensors, n_units):
return tf.nn.leaky_relu(fc_no_activation_layer(in_tensors, n_units))
Finally, let's create a convolutional layer that takes as arguments the input data, kernel size, and number of filters (or units). We will use the same activations used in the fully connected layer. In this case, the output passes through a leaky ReLU activation:
def conv_layer(in_tensors, kernel_size, n_units):
w = tf.get_variable('conv_W',
[kernel_size, kernel_size, in_tensors.get_shape()[3], n_units],
tf.float32,
tf.contrib.layers.xavier_initializer())
b = tf.get_variable('conv_B',
[n_units, ],
tf.float32,
tf.constant_initializer(0.0))
return tf.nn.leaky_relu(tf.nn.conv2d(in_tensors, w, [1, 1, 1, 1], 'SAME') + b)
Now, it's time to create a maxpool_layer. Here, the size of the window and the strides are both squares (quadrates):
def maxpool_layer(in_tensors, sampling):
return tf.nn.max_pool(in_tensors, [1, sampling, sampling, 1], [1, sampling, sampling, 1], 'SAME')
The last thing to define is the dropout, used for regularizing the network. Pretty simple thing to create, but remember that dropout should only be used when training the network, and not when predicting the outputs; therefore, we need to have a conditional operator to define whether to apply dropouts or not:
def dropout(in_tensors, keep_proba, is_training):
return tf.cond(is_training, lambda: tf.nn.dropout(in_tensors, keep_proba), lambda: in_tensors)
Finally, it's time to put it all together and create the model as previously defined. We'll create a model composed of the following layers:
- 2D convolution, 5x5, 32 filters
- 2D convolution, 5x5, 64 filters
- Flattenizer
- Fully connected later, 1,024 units
- Dropout 40%
- Fully connected layer, no activation
- Softmax output
Here's the code:
def model(in_tensors, is_training):
# First layer: 5x5 2d-conv, 32 filters, 2x maxpool, 20% drouput
with tf.variable_scope('l1'):
l1 = maxpool_layer(conv_layer(in_tensors, 5, 32), 2)
l1_out = dropout(l1, 0.8, is_training)
# Second layer: 5x5 2d-conv, 64 filters, 2x maxpool, 20% drouput
with tf.variable_scope('l2'):
l2 = maxpool_layer(conv_layer(l1_out, 5, 64), 2)
l2_out = dropout(l2, 0.8, is_training)
with tf.variable_scope('flatten'):
l2_out_flat = tf.layers.flatten(l2_out)
# Fully collected layer, 1024 neurons, 40% dropout
with tf.variable_scope('l3'):
l3 = fc_layer(l2_out_flat, 1024)
l3_out = dropout(l3, 0.6, is_training)
# Output
with tf.variable_scope('out'):
out_tensors = fc_no_activation_layer(l3_out, N_CLASSES)
return out_tensors
And now, let's write the function to train the model on the training set and test the performance on the test set. Please note that all of the following code belongs to the function train_model function; it's broken down in to pieces just for simplicity of explanation.
The function takes as arguments (other than the training and test sets and their labels) the learning rate, the number of epochs, and the batch size, that is, number of images per training batch. First things first, some TensorFlow placeholders are defined: one for the minibatch of images, one for the minibatch of labels, and the last one to select whether to run for training or not (that's mainly used by the dropout layer):
from sklearn.metrics import classification_report, confusion_matrix
def train_model(X_train, y_train, X_test, y_test, learning_rate, max_epochs, batch_size):
in_X_tensors_batch = tf.placeholder(tf.float32, shape = (None, RESIZED_IMAGE[0], RESIZED_IMAGE[1], 1))
in_y_tensors_batch = tf.placeholder(tf.float32, shape = (None, N_CLASSES))
is_training = tf.placeholder(tf.bool)
Now, let's define the output, metric score, and optimizer. Here, we decided to use the AdamOptimizer and the cross entropy with softmax(logits) as loss:
logits = model(in_X_tensors_batch, is_training)
out_y_pred = tf.nn.softmax(logits)
loss_score = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=in_y_tensors_batch)
loss = tf.reduce_mean(loss_score)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
And finally, here's the code for training the model with minibatches:
with tf.Session() as session:
session.run(tf.global_variables_initializer())
for epoch in range(max_epochs):
print("Epoch=", epoch)
tf_score = []
for mb in minibatcher(X_train, y_train, batch_size, shuffle = True):
tf_output = session.run([optimizer, loss],
feed_dict = {in_X_tensors_batch : mb[0],
in_y_tensors_batch :
b[1],
is_training : True})
tf_score.append(tf_output[1])
print(" train_loss_score=", np.mean(tf_score))
After the training, it's time to test the model on the test set. Here, instead of sending a minibatch, we will use the whole test set. Mind it! is_training should be set as False since we don't want to use the dropouts:
print("TEST SET PERFORMANCE")
y_test_pred, test_loss = session.run([out_y_pred, loss],
feed_dict = {in_X_tensors_batch : X_test, in_y_tensors_batch : y_test, is_training : False})
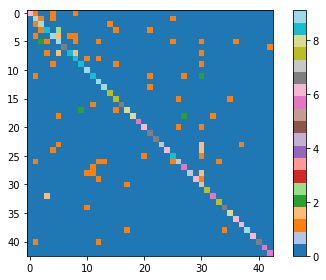
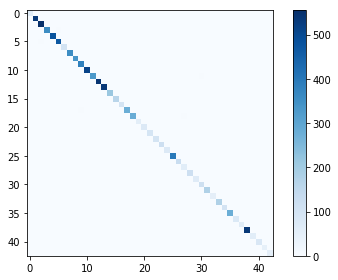
And, as a final operation, let's print the classification report and plot the confusion matrix (and its log2 version) to see the misclassifications:
print(" test_loss_score=", test_loss)
y_test_pred_classified = np.argmax(y_test_pred, axis=1).astype(np.int32)
y_test_true_classified = np.argmax(y_test, axis=1).astype(np.int32)
print(classification_report(y_test_true_classified, y_test_pred_classified))
cm = confusion_matrix(y_test_true_classified, y_test_pred_classified)
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.colorbar()
plt.tight_layout()
plt.show()
# And the log2 version, to enphasize the misclassifications
plt.imshow(np.log2(cm + 1), interpolation='nearest', cmap=plt.get_cmap("tab20"))
plt.colorbar()
plt.tight_layout()
plt.show()
tf.reset_default_graph()
Finally, let's run the function with some parameters. Here, we will run the model with a learning step of 0.001, 256 samples per minibatch, and 10 epochs:
train_model(X_train, y_train, X_test, y_test, 0.001, 10, 256)
Here's the output:
Epoch= 0
train_loss_score= 3.4909246
Epoch= 1
train_loss_score= 0.5096467
Epoch= 2
train_loss_score= 0.26641673
Epoch= 3
train_loss_score= 0.1706828
Epoch= 4
train_loss_score= 0.12737551
Epoch= 5
train_loss_score= 0.09745725
Epoch= 6
train_loss_score= 0.07730477
Epoch= 7
train_loss_score= 0.06734192
Epoch= 8
train_loss_score= 0.06815668
Epoch= 9
train_loss_score= 0.060291935
TEST SET PERFORMANCE
test_loss_score= 0.04581982
This is followed by the classification report per class:
precision recall f1-score support
0 1.00 0.96 0.98 67
1 0.99 0.99 0.99 539
2 0.99 1.00 0.99 558
3 0.99 0.98 0.98 364
4 0.99 0.99 0.99 487
5 0.98 0.98 0.98 479
6 1.00 0.99 1.00 105
7 1.00 0.98 0.99 364
8 0.99 0.99 0.99 340
9 0.99 0.99 0.99 384
10 0.99 1.00 1.00 513
11 0.99 0.98 0.99 334
12 0.99 1.00 1.00 545
13 1.00 1.00 1.00 537
14 1.00 1.00 1.00 213
15 0.98 0.99 0.98 164
16 1.00 0.99 0.99 98
17 0.99 0.99 0.99 281
18 1.00 0.98 0.99 286
19 1.00 1.00 1.00 56
20 0.99 0.97 0.98 78
21 0.97 1.00 0.98 95
22 1.00 1.00 1.00 97
23 1.00 0.97 0.98 123
24 1.00 0.96 0.98 77
25 0.99 1.00 0.99 401
26 0.98 0.96 0.97 135
27 0.94 0.98 0.96 60
28 1.00 0.97 0.98 123
29 1.00 0.97 0.99 69
30 0.88 0.99 0.93 115
31 1.00 1.00 1.00 178
32 0.98 0.96 0.97 55
33 0.99 1.00 1.00 177
34 0.99 0.99 0.99 103
35 1.00 1.00 1.00 277
36 0.99 1.00 0.99 78
37 0.98 1.00 0.99 63
38 1.00 1.00 1.00 540
39 1.00 1.00 1.00 60
40 1.00 0.98 0.99 85
41 1.00 1.00 1.00 47
42 0.98 1.00 0.99 53
avg / total 0.99 0.99 0.99 9803
As you can see, we managed to reach a precision of 0.99 on the test set; also, recall and f1 score have the same score. The model looks stable since the loss in the test set is similar to the one reported in the last iteration; therefore, we're not over-fitting nor under-fitting.
And the confusion matrices:
The following is the log2 version of preceding screenshot: