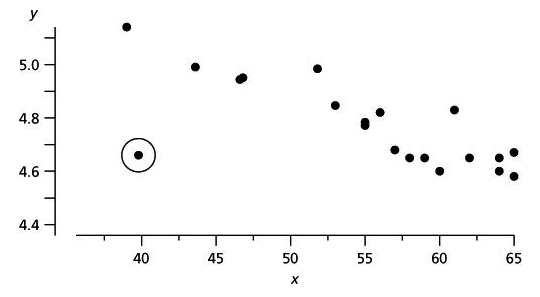
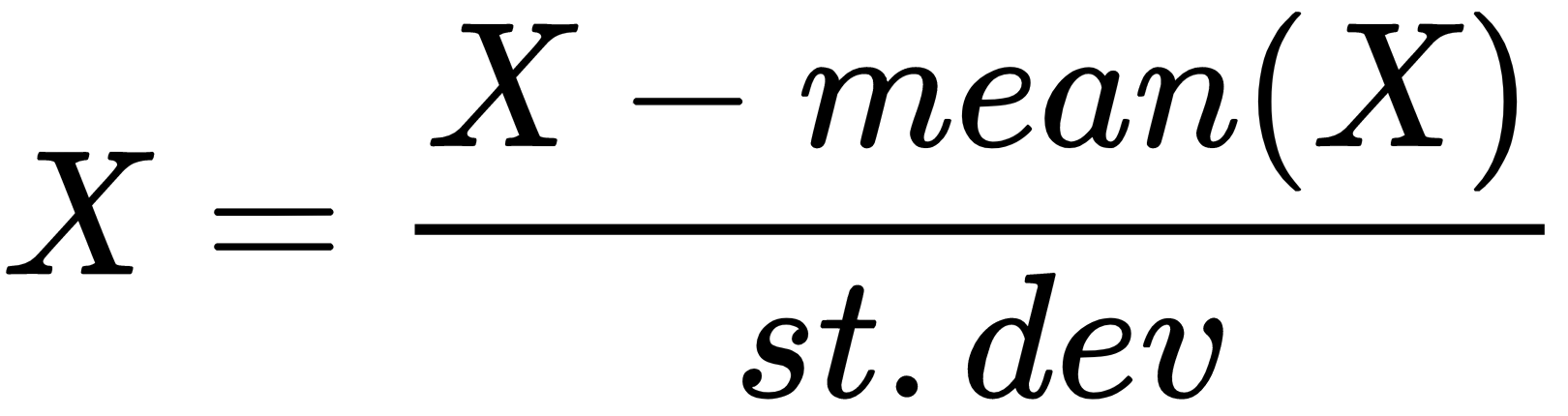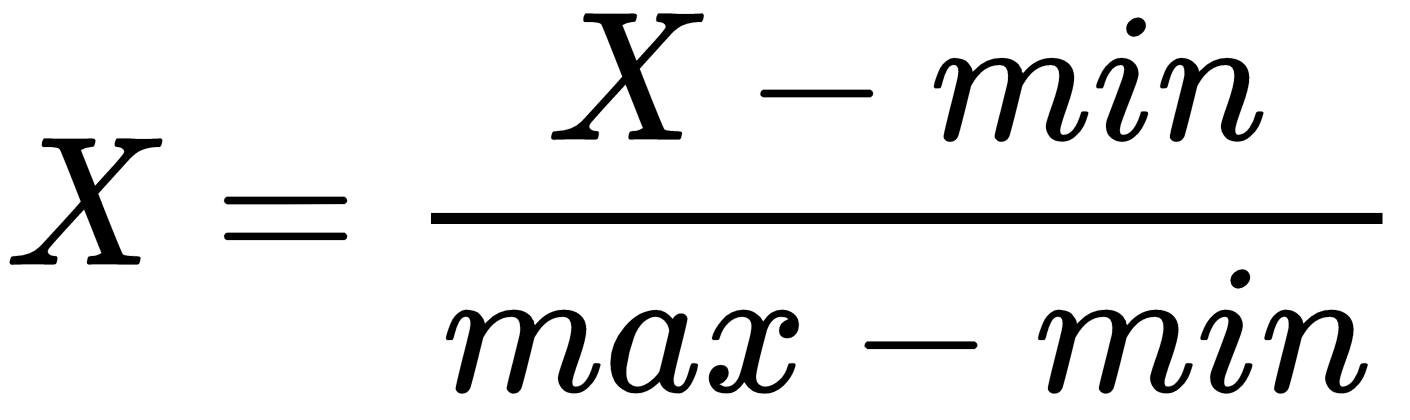The goal of data preprocessing tasks is to prepare the data for a machine learning algorithm in the best possible way, as not all algorithms are capable of addressing issues with missing data, extra attributes, or denormalized values.
-
Book Overview & Buying

-
Table Of Contents

Machine Learning in Java - Second Edition
By :
Machine Learning in Java
By:
Overview of this book
As the amount of data in the world continues to grow at an almost incomprehensible rate, being able to understand and process data is becoming a key differentiator for competitive organizations. Machine learning applications are everywhere, from self-driving cars, spam detection, document search, and trading strategies, to speech recognition. This makes machine learning well-suited to the present-day era of big data and Data Science. The main challenge is how to transform data into actionable knowledge.
Machine Learning in Java will provide you with the techniques and tools you need. You will start by learning how to apply machine learning methods to a variety of common tasks including classification, prediction, forecasting, market basket analysis, and clustering. The code in this book works for JDK 8 and above, the code is tested on JDK 11.
Moving on, you will discover how to detect anomalies and fraud, and ways to perform activity recognition, image recognition, and text analysis. By the end of the book, you will have explored related web resources and technologies that will help you take your learning to the next level.
By applying the most effective machine learning methods to real-world problems, you will gain hands-on experience that will transform the way you think about data.
Table of Contents (13 chapters)
Preface
 Free Chapter
Free Chapter
Applied Machine Learning Quick Start
Java Libraries and Platforms for Machine Learning
Basic Algorithms - Classification, Regression, and Clustering
Customer Relationship Prediction with Ensembles
Affinity Analysis
Recommendation Engines with Apache Mahout
Fraud and Anomaly Detection
Image Recognition with Deeplearning4j
Activity Recognition with Mobile Phone Sensors
Text Mining with Mallet - Topic Modeling and Spam Detection
What Is Next?
Other Books You May Enjoy