

A Belief or Bayesian network is a concept already explored in Chapter 4, Bayesian Networks and Hidden Markov Models. In this particular case, we are going to consider Belief Networks where there are visible and latent variables, organized into homogeneous layers. The first layer always contains the input (visible) units, while all the remaining ones are latent. Hence, a DBN can be structured as a stack of RBMs, where each hidden layer is also the visible one of the subsequent RBM, as shown in the following diagram (the number of units can be different for each layer):
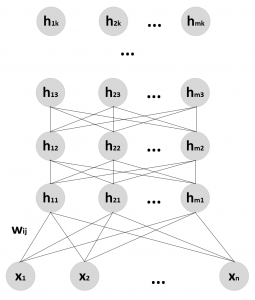
Structure of a generic Deep Belief Network
The learning procedure is usually greedy and step-wise (as proposed in A fast learning algorithm for deep belief nets, Hinton G. E., Osindero S., Teh Y. W., Neural Computation, 18/7). The first RBM is trained with the dataset and optimized to reconstruct the original distribution using the CD-k algorithm. At this point, the internal (hidden) representations are employed as input...