

We have seen that the factors extracted by a PCA are decorrelated, but not independent. A classic example is the cocktail party: we have a recording of many overlapped voices and we would like to separate them. Every single voice can be modeled as a random process and it's possible to assume that they are statistically independent (this means that the joint probability can be factorized using the marginal probabilities of each source). Using FA or PCA, we are able to find uncorrelated factors, but there's no way to assess whether they are also independent (normally, they aren't). In this section, we are going to study a model that is able to produce sparse representations (when the dictionary isn't under-complete) with a set of statistically independent components.
Let's assume we have a zero-centered and whitened dataset X sampled from N(0, I) and noiseless linear transformation:
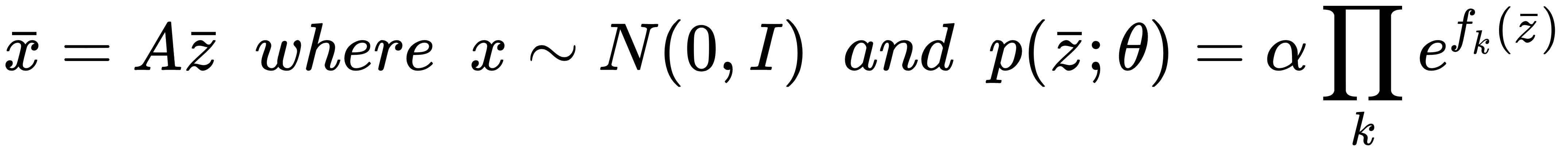
In this case, the prior over, z, is modeled as a product of independent variables...