

Following the objective function shown here, in the original GAN paper:
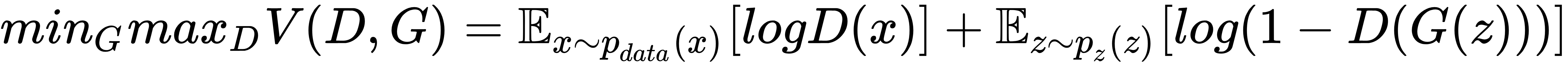
Where:
- x: Data
- pg: Generator's distribution over data x
- p(z): A priori on input noise variable
- G(Z,θg): Map prior to data space
- G: Differentiable function represented by multi-layer perceptron with parameters θg
- D(x,θg): Discriminator-second multilayer perceptron which outputs a single scalar
- D(x): The probability that x came from the data rather than pg
The objective is to train D to maximize the probability of assigning the correct label to both training examples and samples from G. We simultaneously train G to minimize Log(1-D(G(Z))); the optimal discriminator DG(X) is given by:

Where is the real distribution, which can be found by rearranging the terms shown in the preceding example: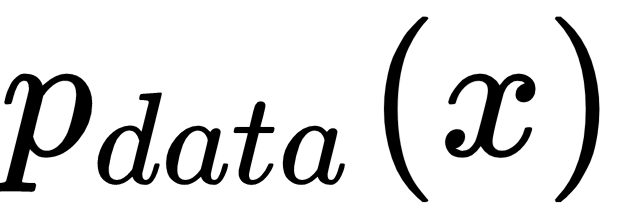

The assumption is that if we train D(x) more and more, it will come closer and closer to DG(X) and our GAN training becomes better and better. For optimal generator,
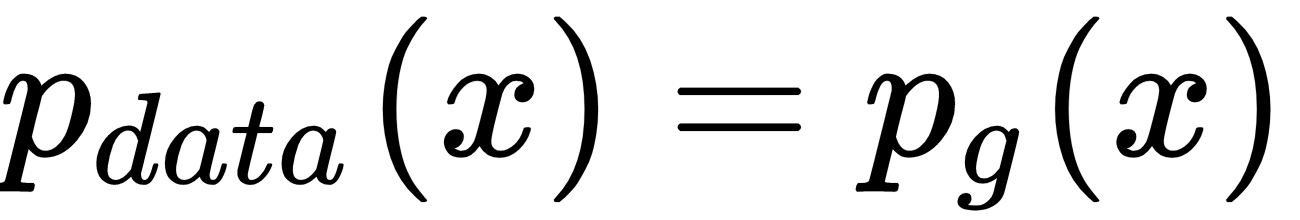
, the optimal generator has a value of 0.5. Notice that...