





Coming to the forward-backward algorithm, we are now trying to compute the conditional distribution of the hidden state given the observations.
Taking the example of our robot localization, we are trying to now find the probability distribution of the robot's position at some time instance given the sensor readings:
Forward-backward algorithm: P(Zk|X)
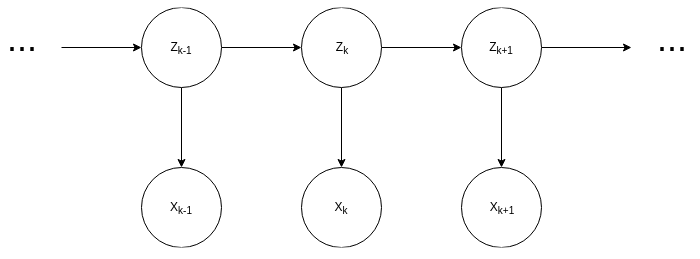
Figure 3.5: HMM showing three time slices, k-1, k, and k+1
Now, since we have been given all the observed variables in the model, we can say that the value of P(Zk|X) is going to be proportional to the joint distribution over Zk and X:
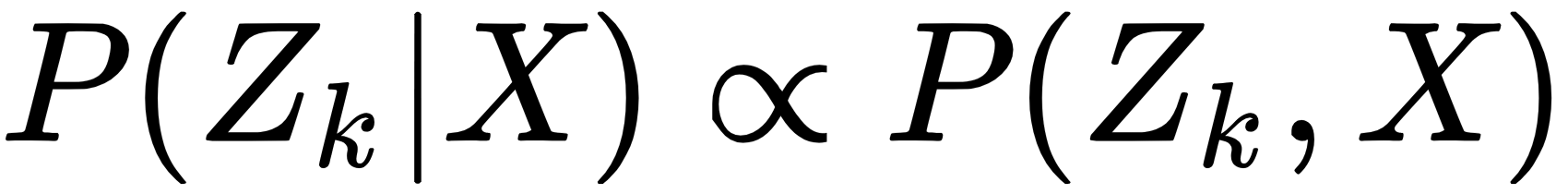
Now, we know that we can write X={X1:k, Xk+1:n}. Replacing this in the preceding equation, we get:
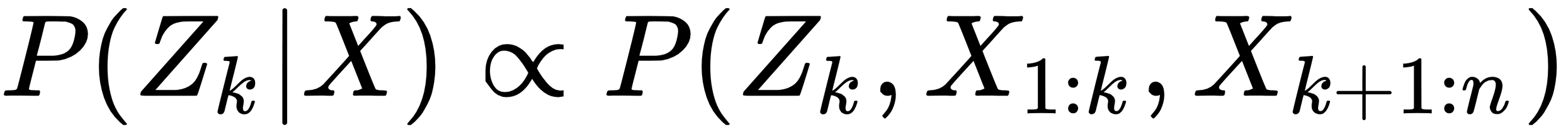
We can apply the chain rule in the preceding equation to write it as:
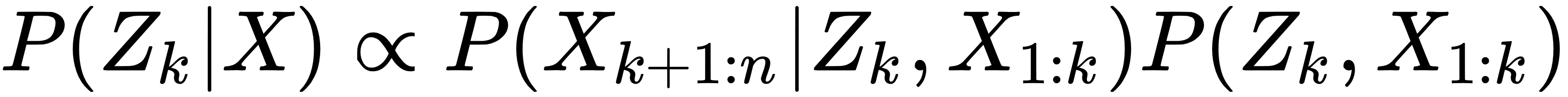
From our model structure, we know that 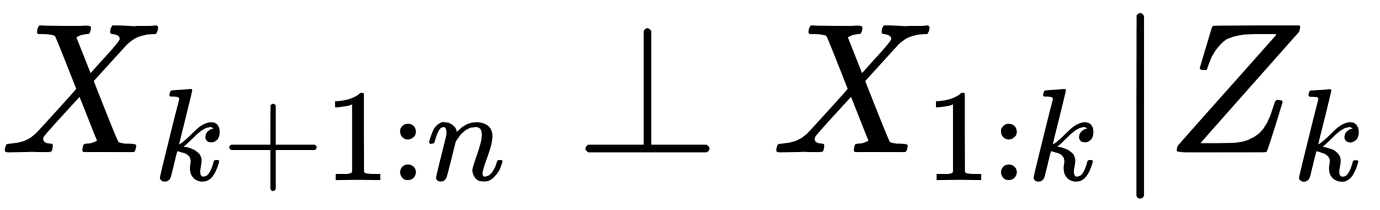 , and using this independence property we can...
, and using this independence property we can...







