

The learning process of a neural network is configured as an iterative process of the optimization of the weights and is therefore of the supervised type. The weights are modified because of the network's performance on a set of examples belonging to the training set, that is, the set where you know the classes that the examples belong to.
The aim is to minimize the loss function, which indicates the degree to which the behavior of the network deviates from the desired behavior. The performance of the network is then verified on a testing set consisting of objects (for example, images in an image classification problem) other than those in the training set.
A commonly used supervised learning algorithm is the backpropagation algorithm. The basic steps of the training procedure are as follows:
Initialize the net with random weights
For all training cases, follow these steps:
Forward pass: Calculates the network's error, that is, the difference between the desired output and the actual output
Backward pass: For all layers, starting with the output layer back to input layer:
i: Shows the network layer's output with the correct input (error function).
ii: Adapts the weights in the current layer to minimize the error function. This is backpropagation's optimization step.
The training process ends when the error on the validation set begins to increase because this could mark the beginning of a phase overfitting, that is, the phase in which the network tends to interpolate the training data at the expense of generalizability.
The availability of efficient algorithms to optimize weights, therefore, constitutes an essential tool for the construction of neural networks. The problem can be solved with an iterative numerical technique called Gradient Descent (GD). This technique works according to the following algorithm:
Randomly choose initial values for the parameters of the model
Compute the gradient G of the error function with respect to each parameter of the model
Change the model's parameters so that they move in the direction of decreasing the error, that is, in the direction of -G
Repeat steps 2 and 3 until the value of G approaches zero
The gradient (G) of the error function E provides the direction in which the error function with the current values has the steeper slope; so to decrease E, we have to make some small steps in the opposite direction, -G.
By repeating this operation several times in an iterative manner, we move down towards the minimum of E, to reach a point where G = 0, in such a way that no further progress is possible:
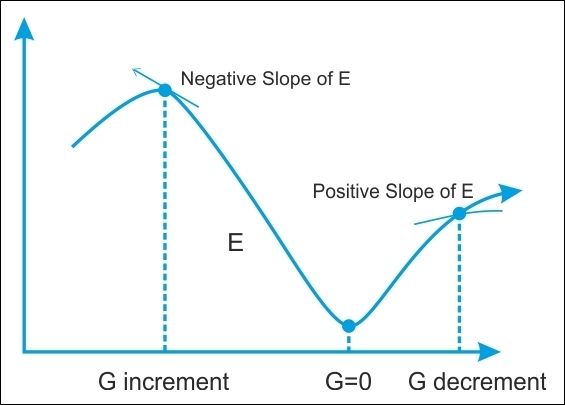
Figure 10: Searching for the minimum for the error function E. We move in the direction in which the gradient G of the function E is minimal.
In GD optimization, we compute the cost gradient based on the complete training set, so we sometimes also call it batch GD. In the case of very large datasets, using GD can be quite costly, since we are only taking a single step for one pass over the training set. The larger the training set, the more slowly our algorithm updates the weights, and the longer it may take until it converges at the global cost minimum.
The fastest method of gradient descent is Stochastic Gradient Descent (SGD), and for this reason, it is widely used in deep neural networks. In SGD, we use only one training sample from the training set to do the update for a parameter in a particular iteration.
Here, the term stochastic comes from the fact that the gradient based on a single training sample is a stochastic approximation of the true cost gradient. Due to its stochastic nature, the path towards the global cost minimum is not direct, as in GD, but may zigzag if we are visualizing the cost surface in a 2D space:
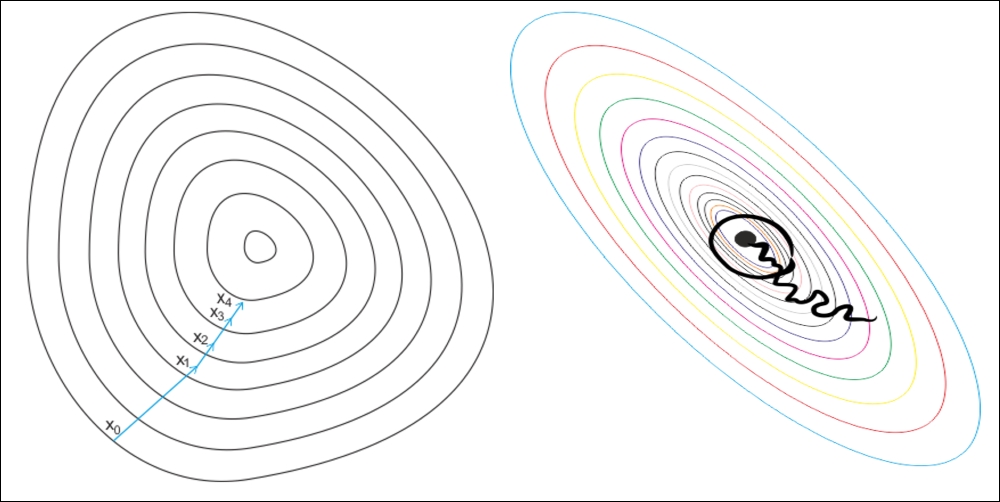
Figure 11: GD versus SGD: the gradient descent (left figure) ensures that each update in the weights is done in the right direction: the direction that minimizes the cost function. With the growth in the dataset's size, and more complex computations in each step, SGD (right figure) is preferred in these cases. Here, updates to the weights are done as each sample is processed and, as such, subsequent calculations already use improved weights. Nonetheless, this very reason leads to some misdirection in minimizing the error function.