

In the previous chapter, we briefly mentioned that one of the ways to improve the stability of PG methods is to reduce the variance of the gradient. Now let's try to understand why this is important and what it means to reduce the variance. In statistics, variance is the expected square deviation of a random variable from the expected value of this variable.
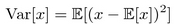
Variance shows us how far values are dispersed from the mean. When variance is high, the random variable can take values deviated widely from the mean. On the following plot, there is a normal (Gaussian) distribution with the same value of mean  , but with different values for the variance.
, but with different values for the variance.

Figure 1: The effect of variance on Gaussian distribution
Now let's return to PG. It has already been stated in the previous chapter, that the method's idea is to increase the probability of good actions and decrease the chance of bad ones. In math notation, our PG was written as  . The scaling factor Q(s, a) specifies how much we want...
. The scaling factor Q(s, a) specifies how much we want...