

From the practical point of view, communicating with several parallel environments is simple and we've already done this in the previous chapter, but haven't stated it explicitly. In the A2C agent, we passed an array of Gym environments into the ExperienceSource class, which switched it into the round-robin data gathering mode: every time we asked for a transition from the experience source, the class uses the next environment from our array (of course, keeping the state for every environment). This simple approach is equivalent to parallel communication with environments, but with one single difference: communication is not parallel in the strict sense, but performed in a serial way. However, samples from our experience source are shuffled. This idea is shown in the following diagram:
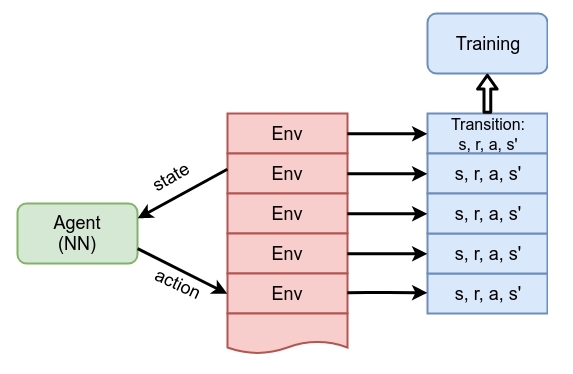
Figure 1: Agent training from multiple environments in parallel
This method worked fine and helped us to get convergence in the A2C method, but it is still not perfect in terms of computing...