

The first improvement that we'll implement and evaluate is quite an old one. It was first introduced in the paper by Richard Sutton ([2] Sutton, 1988). To get the idea, let's look at the Bellman update used in Q-learning once again.
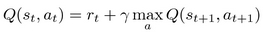
This equation is recursive, which means that we can express  in terms of itself, which gives us this result:
in terms of itself, which gives us this result:
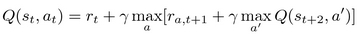
Value ra,t+1 means local reward at time t+1, after issuing action a. However, if we assume that our action a at the step t+1 was chosen optimally, or close to optimally, we can omit maxa and operation and obtain this:
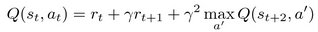
This value could be unrolled again and again any number of times. As you may guess, this unrolling can be easily applied to our DQN update by replacing one-step transition sampling with longer transition sequences of n-steps. To understand why this unrolling will help us to speed up training, let's consider the example illustrated below. Here we have a simple environment of four states, s1, s2, s3, s4, and the only action available...