

In the early 2000s, search engines on the World Wide Web were competing to bring improved and accurate results. One of the key challenges was about indexing this large data, keeping a limit over the cost factor on hardware. Doug Cutting and Mike Caferella started development on Nutch in 2002, which would include a search engine and web crawler. However, the biggest challenge was to index billions of pages due to lack of matured cluster management systems. In 2003, Google published a research paper on Google's distributed filesystem (GFS) (https://ai.google/research/pubs/pub51). This helped them devise a distributed filesystem for Nutch called NDFS. In 2004, Google introduced MapReduce programming to the world. The concept of MapReduce was inspired from the Lisp programming language. In 2006, Hadoop was created under the Lucene umbrella. In the same year, Doug was employed by Yahoo to solve some of the most challenging issues with Yahoo Search, which was barely surviving. The following is a timeline of these and later events:
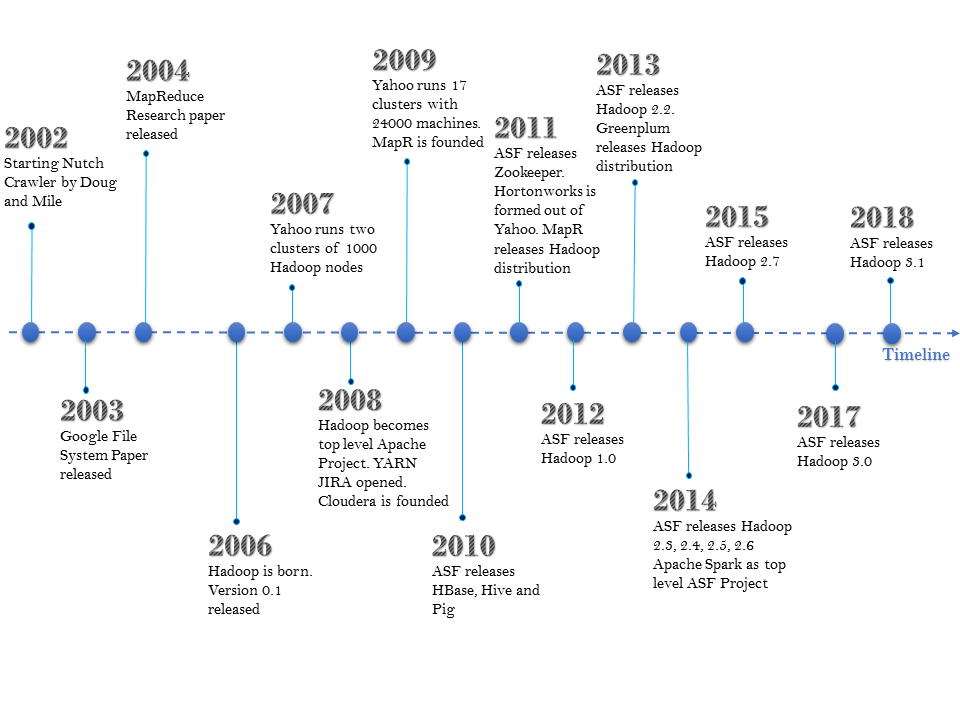
In 2007, many companies such as LinkedIn, Twitter, and Facebook started working on this platform, whereas Yahoo's production Hadoop cluster reached the 1,000-node mark. In 2008, Apache Software Foundation (ASF) moved Hadoop out of Lucene and graduated it as a top-level project. This was the time when the first Hadoop-based commercial system integration company, called Cloudera, was formed.
In 2009, AWS started giving MapReduce hosting capabilities, whereas Yahoo achieved the 24k nodes production cluster mark. This was the year when another SI (System Integrator) called MapR was founded. In 2010, ASF released HBase, Hive, and Pig to the world. In the year 2011, the road ahead for Yahoo looked difficult, so original Hadoop developers from Yahoo separated from it, and formed a company called Hortonworks. Hortonworks offers 100% open source implementation of Hadoop. The same team also become part of the Project Management Committee of ASF.
In 2012, ASF released the first major release of Hadoop 1.0, and immediately next year, it released Hadoop 2.X. In subsequent years, the Apache open source community continued with minor releases of Hadoop due to its dedicated, diverse community of developers. In 2017, ASF released Apache Hadoop version 3.0. On similar lines, companies such as Hortonworks, Cloudera, MapR, and Greenplum are also engaged in providing their own distribution of the Apache Hadoop ecosystem.