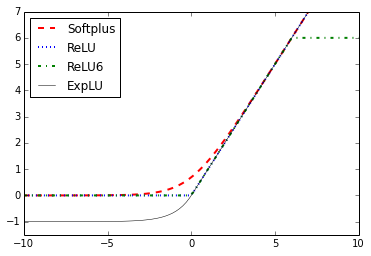
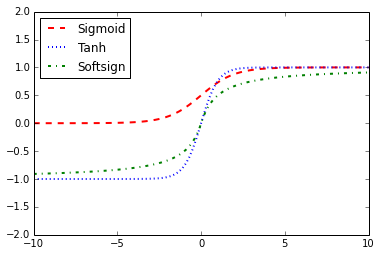
Activation functions are the key for neural networks to approximate non-linear outputs and adapt to non-linear features. They introduce non-linear operations into neural networks. If we are careful as to which activation functions are selected and where we put them, they are very powerful operations that we can tell TensorFlow to fit and optimize.
-
Book Overview & Buying

-
Table Of Contents

TensorFlow Machine Learning Cookbook - Second Edition
By :
TensorFlow Machine Learning Cookbook
By:
Overview of this book
TensorFlow is an open source software library for Machine Intelligence. The independent recipes in this book will teach you how to use TensorFlow for complex data computations and allow you to dig deeper and gain more insights into your data than ever before.
With the help of this book, you will work with recipes for training models, model evaluation, sentiment analysis, regression analysis, clustering analysis, artificial neural networks, and more. You will explore RNNs, CNNs, GANs, reinforcement learning, and capsule networks, each using Google's machine learning library, TensorFlow. Through real-world examples, you will get hands-on experience with linear regression techniques with TensorFlow. Once you are familiar and comfortable with the TensorFlow ecosystem, you will be shown how to take it to production.
By the end of the book, you will be proficient in the field of machine intelligence using TensorFlow. You will also have good insight into deep learning and be capable of implementing machine learning algorithms in real-world scenarios.
Table of Contents (13 chapters)
Preface
 Free Chapter
Free Chapter
Getting Started with TensorFlow
The TensorFlow Way
Linear Regression
Support Vector Machines
Nearest-Neighbor Methods
Neural Networks
Natural Language Processing
Convolutional Neural Networks
Recurrent Neural Networks
Taking TensorFlow to Production
More with TensorFlow
Other Books You May Enjoy
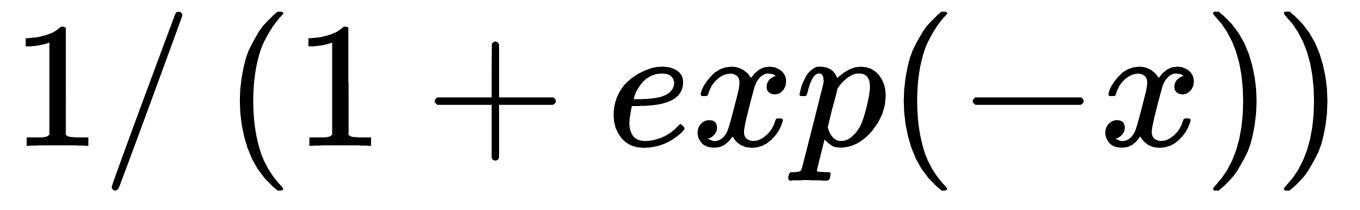 . The sigmoid function is not used very often because of its tendency to zero-out the backpropagation terms during training. It appears as follows:
. The sigmoid function is not used very often because of its tendency to zero-out the backpropagation terms during training. It appears as follows: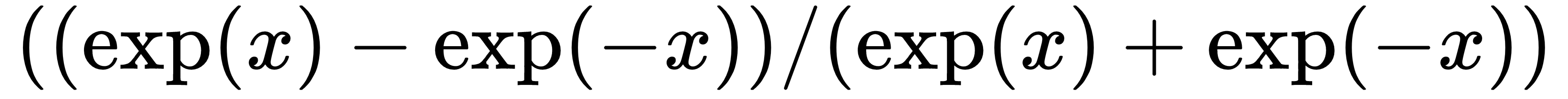 . This activation function is as follows:
. This activation function is as follows: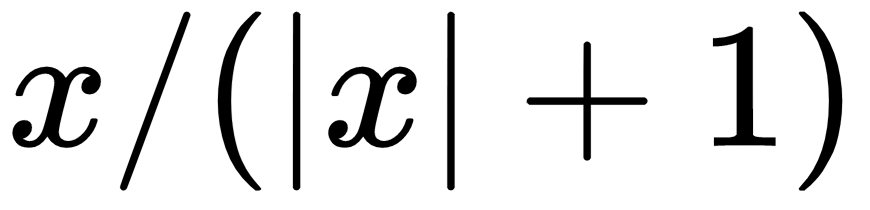 . The softsign function is supposed to be a continuous (but not smooth) approximation to the sign function. See the following code:
. The softsign function is supposed to be a continuous (but not smooth) approximation to the sign function. See the following code: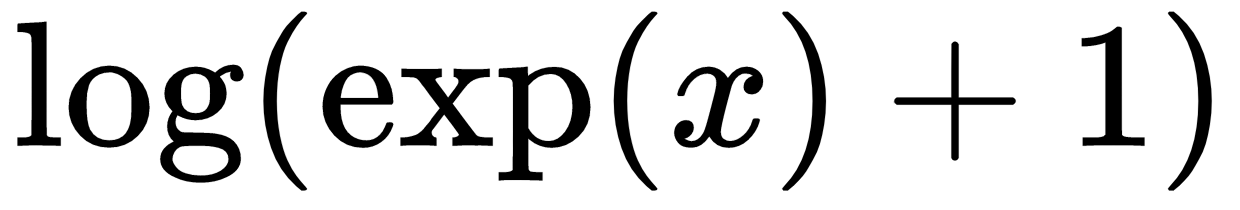 . It appears as follows:
. It appears as follows: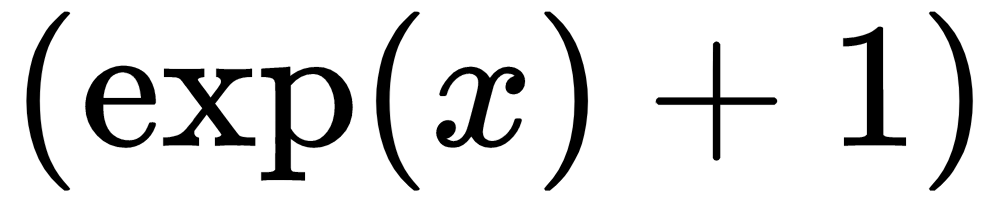 if x < 0 else x. It appears as follows:
if x < 0 else x. It appears as follows: