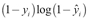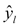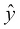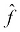-
Book Overview & Buying

-
Table Of Contents

Machine Learning for Finance
By :
Machine Learning for Finance
By:
Overview of this book
Machine Learning for Finance explores new advances in machine learning and shows how they can be applied across the financial sector, including insurance, transactions, and lending. This book explains the concepts and algorithms behind the main machine learning techniques and provides example Python code for implementing the models yourself.
The book is based on Jannes Klaas’ experience of running machine learning training courses for financial professionals. Rather than providing ready-made financial algorithms, the book focuses on advanced machine learning concepts and ideas that can be applied in a wide variety of ways.
The book systematically explains how machine learning works on structured data, text, images, and time series. You'll cover generative adversarial learning, reinforcement learning, debugging, and launching machine learning products. Later chapters will discuss how to fight bias in machine learning. The book ends with an exploration of Bayesian inference and probabilistic programming.
Table of Contents (15 chapters)
Machine Learning for Finance

Contributors
Preface
Other Books You May Enjoy
 Free Chapter
Free Chapter
Neural Networks and Gradient-Based Optimization
Applying Machine Learning to Structured Data
Utilizing Computer Vision
Understanding Time Series
Parsing Textual Data with Natural Language Processing
Using Generative Models
Reinforcement Learning for Financial Markets
Privacy, Debugging, and Launching Your Products
Fighting Bias
Bayesian Inference and Probabilistic Programming
Index