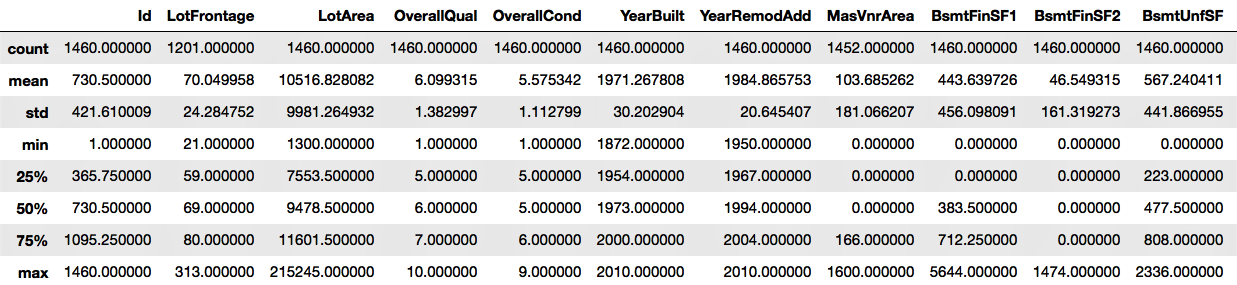
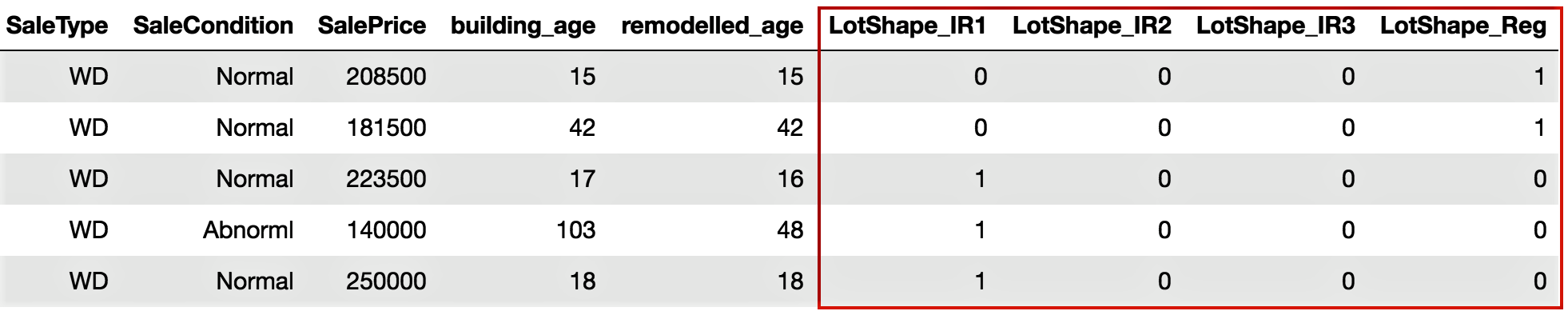
In real life, it is often hard to get a complete and clean dataset formatted exactly as we need it. The data we receive often cannot be directly used in statistical or machine learning algorithms. We need to manipulate the raw data so that the processed data can be used for further analysis and modelling purposes. To begin with, we need to import the required packages, such as pandas, and read our dataset into Python.
-
Book Overview & Buying

-
Table Of Contents

Ensemble Machine Learning Cookbook
By :
Ensemble Machine Learning Cookbook
By:
Overview of this book
Ensemble modeling is an approach used to improve the performance of machine learning models. It combines two or more similar or dissimilar machine learning algorithms to deliver superior intellectual powers. This book will help you to implement popular machine learning algorithms to cover different paradigms of ensemble machine learning such as boosting, bagging, and stacking.
The Ensemble Machine Learning Cookbook will start by getting you acquainted with the basics of ensemble techniques and exploratory data analysis. You'll then learn to implement tasks related to statistical and machine learning algorithms to understand the ensemble of multiple heterogeneous algorithms. It will also ensure that you don't miss out on key topics, such as like resampling methods. As you progress, you’ll get a better understanding of bagging, boosting, stacking, and working with the Random Forest algorithm using real-world examples. The book will highlight how these ensemble methods use multiple models to improve machine learning results, as compared to a single model. In the concluding chapters, you'll delve into advanced ensemble models using neural networks, natural language processing, and more. You’ll also be able to implement models such as fraud detection, text categorization, and sentiment analysis.
By the end of this book, you'll be able to harness ensemble techniques and the working mechanisms of machine learning algorithms to build intelligent models using individual recipes.
Table of Contents (14 chapters)
Preface
 Free Chapter
Free Chapter
Get Closer to Your Data
Getting Started with Ensemble Machine Learning
Resampling Methods
Statistical and Machine Learning Algorithms
Bag the Models with Bagging
When in Doubt, Use Random Forests
Boosting Model Performance with Boosting
Blend It with Stacking
Homogeneous Ensembles Using Keras
Heterogeneous Ensemble Classifiers Using H2O
Heterogeneous Ensemble for Text Classification Using NLP
Homogenous Ensemble for Multiclass Classification Using Keras
Other Books You May Enjoy