

Since time immemorial, human beings have built tools and machines to simplify their work and reduce the overall effort needed to complete many different tasks. Even without knowing any physical law, they invented levers (formally described for the first time by Archimedes), instruments, and more complex machines to carry out longer and more sophisticated procedures. Hammering a nail became easier and more painless thanks to a simple trick, and so did moving heavy stones or wood using a cart. But, what's the difference between these two examples? Even if the latter is still a simple machine, its complexity allows a person to carry out a composite task without thinking about each step. Some fundamental mechanical laws play a primary role in allowing a horizontal force to contrast gravity efficiently, but neither human beings, nor horses or oxen, knew anything about them. The primitive people simply observed how a genial trick (the wheel) could improve their lives.
The lesson we've learned is that a machine is never efficient or trendy without a concrete possibility to use it with pragmatism. A machine is immediately considered useful and destined to be continuously improved if its users can easily understand what tasks can be completed with less effort or automatically. In the latter case, some intelligence seems to appear next to cogs, wheels, or axles. So, a further step can be added to our evolution list: automatic machines, built (nowadays, we'd say programmed) to accomplish specific goals by transforming energy into work. Wind or watermills are some examples of elementary tools that are able to carry out complete tasks with minimal (compared to a direct activity) human control.
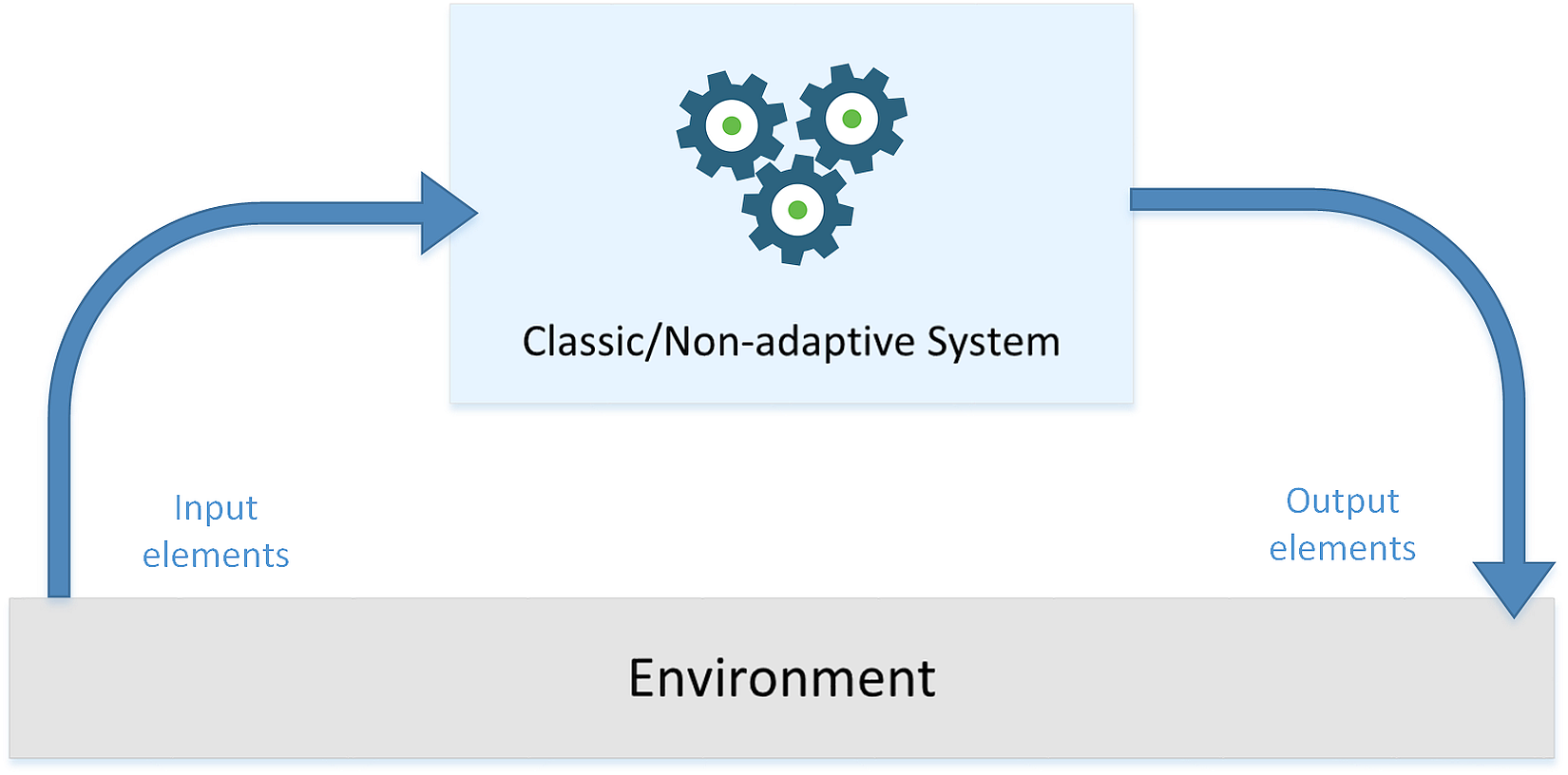
In the following diagram, there's a generic representation of a classical system that receives some input values, processes them, and produces output results:
But again, what's the key to the success of a mill? It's not hasty at all to say that human beings have tried to transfer some intelligence into their tools since the dawn of technology. Both the water in a river and the wind show a behavior that we can simply call flowing. They have a lot of energy to give us free of any charge, but a machine should have some awareness to facilitate this process. A wheel can turn around a fixed axle millions of times, but the wind must find a suitable surface to push on. The answer seems obvious, but you should try to think about people without any knowledge or experience; even if implicitly, they started a brand new approach to technology. If you prefer to reserve the word intelligence to more recent results, it's possible to say that the path started with tools, moved first to simple machines, and then moved to smarter ones.
Without further intermediate (but no less important) steps, we can jump into our epoch and change the scope of our discussion. Programmable computers are widespread, flexible, and more and more powerful instruments; moreover, the diffusion of the internet allowed us to share software applications and related information with minimal effort. The word-processing software that I'm using, my email client, a web browser, and many other common tools running on the same machine, are all examples of such flexibility. It's undeniable that the IT revolution dramatically changed our lives and sometimes improved our daily jobs, but without machine learning (and all its applications), there are still many tasks that seem far out of the computer domain. Spam filtering, Natural Language Processing (NLP), visual tracking with a webcam or a smartphone, and predictive analysis are only a few applications that revolutionized human-machine interaction and increased our expectations. In many cases, they transformed our electronic tools into actual cognitive extensions that are changing the way we interact with many daily situations. They achieved this goal by filling the gap between human perception, language, reasoning, and model and artificial instruments.
Here's a schematic representation of an adaptive system:

Such a system isn't based on static or permanent structures (model parameters and architectures), but rather on a continuous ability to adapt its behavior to external signals (datasets or real-time inputs) and, like a human being, to predict the future using uncertain and fragmentary pieces of information.
Before moving on with a more specific discussion, let's briefly define the different kinds of system analysis that can be performed. These techniques are often structured as a sequence of specific operations whose goal is increasing the overall domain knowledge and allowing answering specific questions, however, in some cases, it's possible to limit the process to a single step in order to meet specific business needs. I always suggest to briefly consider them all, because many particular operations make sense only when some conditions are required. A clear understanding of the problem and its implications is the best way to make the right decisions, also taking into consideration possible future developments.