

Let's consider a dataset of real-value vectors drawn from a data generating process pdata:
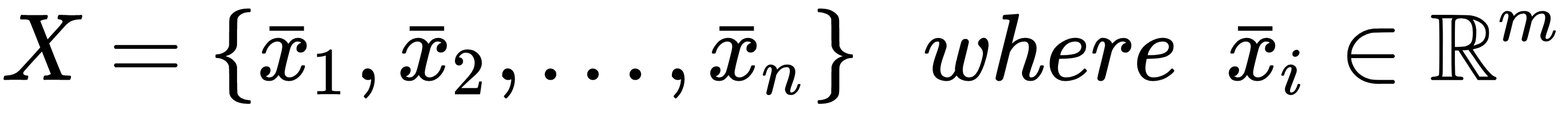
Each input vector is associated with a real value yi:
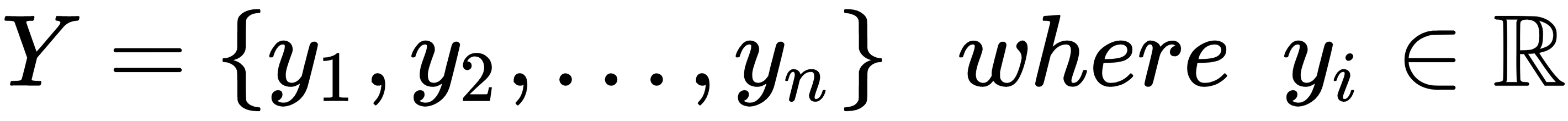
A linear model is based on the assumption that it's possible to approximate the output values through a regression process based on this rule:

In other words, the strong assumption is that our dataset and all other unknown points lie in the volume defined by a hyperplane and random normal noise that depends on the single point. In many cases, the covariance matrix is Σ = σ2Im (that is, homoscedastic noise); hence, the noise has the same impact on all the features. Whenever this doesn't happen (that is, when the noise is heteroscedastic), it's not possible to simplify the expression of Σ. It's helpful to understand that this situation is more common than expected...