Once the overall descriptive knowledge has been gathered and the awareness about the underlying causes is satisfactory, it's possible to create predictive models. The goal of these models is to infer future outcomes according to the history and the structure of the model itself. In many cases, this phase is analyzed together with the next one because we are seldom interested in a free evolution of the system (for example, how the temperature will change in the next month), but rather in the ways we can influence the output.
That said, let's focus only on the predictions, considering the most important elements that should be taken into account. The first consideration is about the nature of the processes. We don't need machine learning for deterministic processes unless their complexity is so high that we're forced to consider them as black boxes. The vast majority of examples we are going to discuss are about stochastic processes where the uncertainty cannot be removed. For example, we know that the temperature in a day can be modeled as a conditional probability (for example, a Gaussian) dependent on the previous observations. Therefore, a prediction sets out not to turn the system into a deterministic one, which is impossible, but to reduce the variance of the distribution, so that the probability is high only for a short range of temperatures. On the other hand, as we know that many latent factors work behind the scene, we can never accept a model based on spiky distributions (for example, on a single outcome with probability 1) because this choice would have a terribly negative impact on the final accuracy.
If our model is parameterized with variables subject to the learning process (for example, the means and covariance matrices of the Gaussians), our goal is to find out the optimal balance in the so-called bias-variance trade-off. As this chapter is an introductory one, we are not formalizing the concepts with mathematical formulas, but we need a practical definition (further details can be found in Bonaccorso G., Mastering Machine Learning Algorithms, Packt, 2018).
The common term to define a statistical predictive model is an estimator. Hence the bias of an estimator is the measurable effect of incorrect assumptions and learning procedures. In other words, if the mean of a process is 5.0 and our estimations have a mean of 3.0, we can say the model is biased. Considering the previous example, we are working with a biased estimator if the expected value of the error between the observed value and the prediction is not null. It's important to understand that we are not saying that every single estimation must have a null error, but while collecting enough samples and computing the mean, its value should be very close to zero (it can be zero only with infinite samples). Whenever it is rather larger than zero, it means that our model is not able to predict training values correctly. It's obvious that we are looking for unbiased estimators that, on average, yield accurate predictions.
On the other hand, the variance of an estimator is a measure of the robustness in the presence of samples not belonging to the training set. At the beginning of this section, we said that our processes are normally stochastic. This means that any dataset must be considered as drawn from a specific data-generating process pdata. If we have enough representative elements xi ∈ X, we can suppose that training a classifier using the limited dataset X leads to a model that is able to classify all potential samples that can be drawn from pdata.
For example, if we need to model a face classifier whose context is limited to portraits (no further face poses are allowed), we can collect a number of portraits of different individuals. Our only concern is not to exclude categories that can be present in real life. Let's assume that we have 10,000 images of individuals of different ages and genders, but we don't have any portraits with a hat. When the system is in production, we receive a call from our customer saying that the system misclassifies many pictures. After analysis, we discover that they always represent people wearing hats. It's clear that our model is not responsible for the error because it has been trained with samples representing only a region of the data generating process. Therefore, in order to solve the problem, we collect other samples and we repeat the training process. However, now we decide to use a more complex model, expecting that it will work better. Unfortunately, we observe a worse validation accuracy (for example, the accuracy on a subset that is not used in the training phase), together with a higher training accuracy. What happened here?
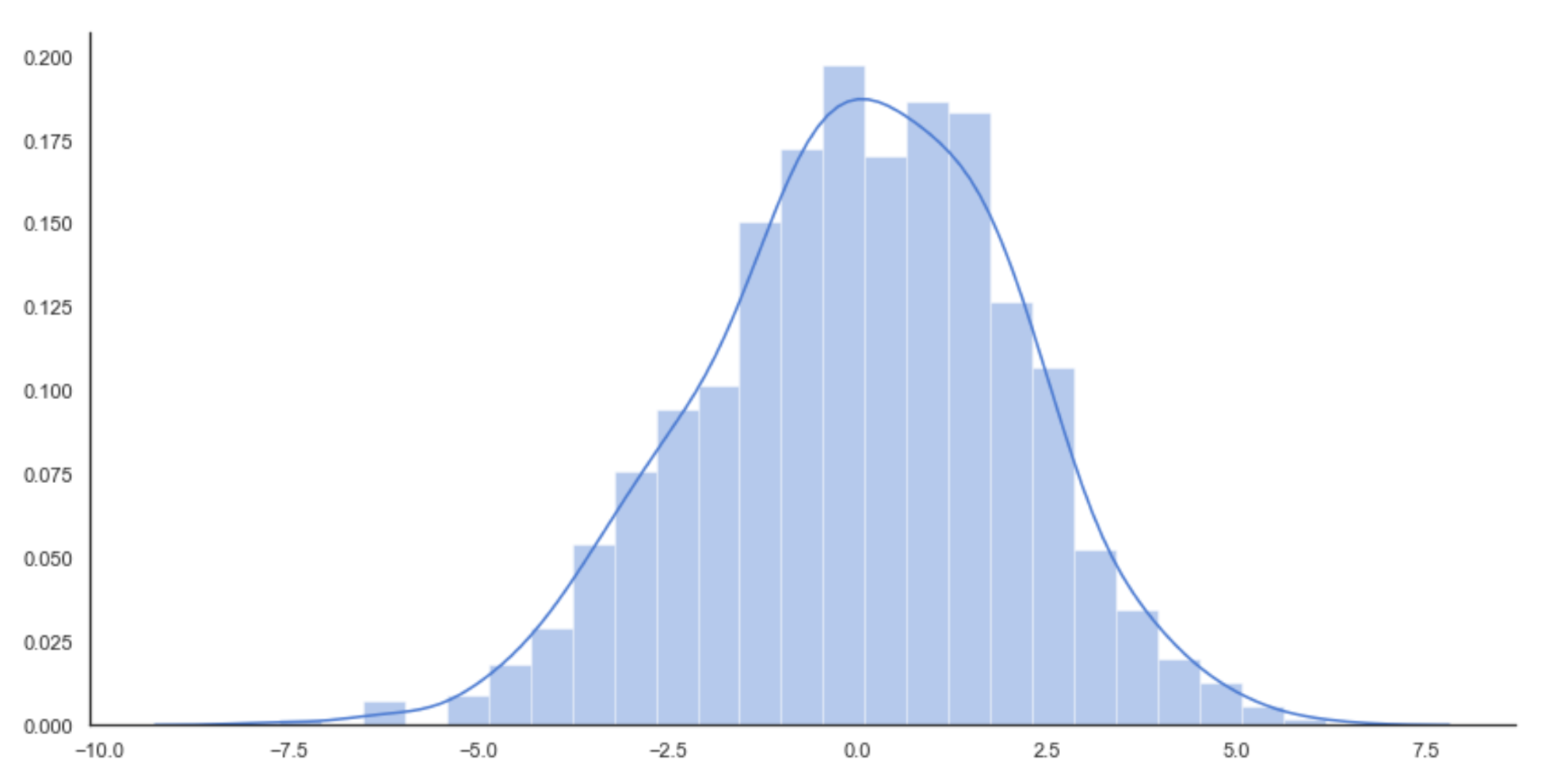
When an estimator learns to classify the training set perfectly but its ability on never-seen samples is poor, we say that it is overfitted and its variance is too high for the specific task (conversely, an underfitted model has a large bias and all predictions are very inaccurate). Intuitively, the model has learned too much about the training data and it has lost the ability to generalize. To better understand this concept, let's look at a Gaussian data generating process, as shown in the following graph:
Original data generating process (solid line) and sampled data histogram
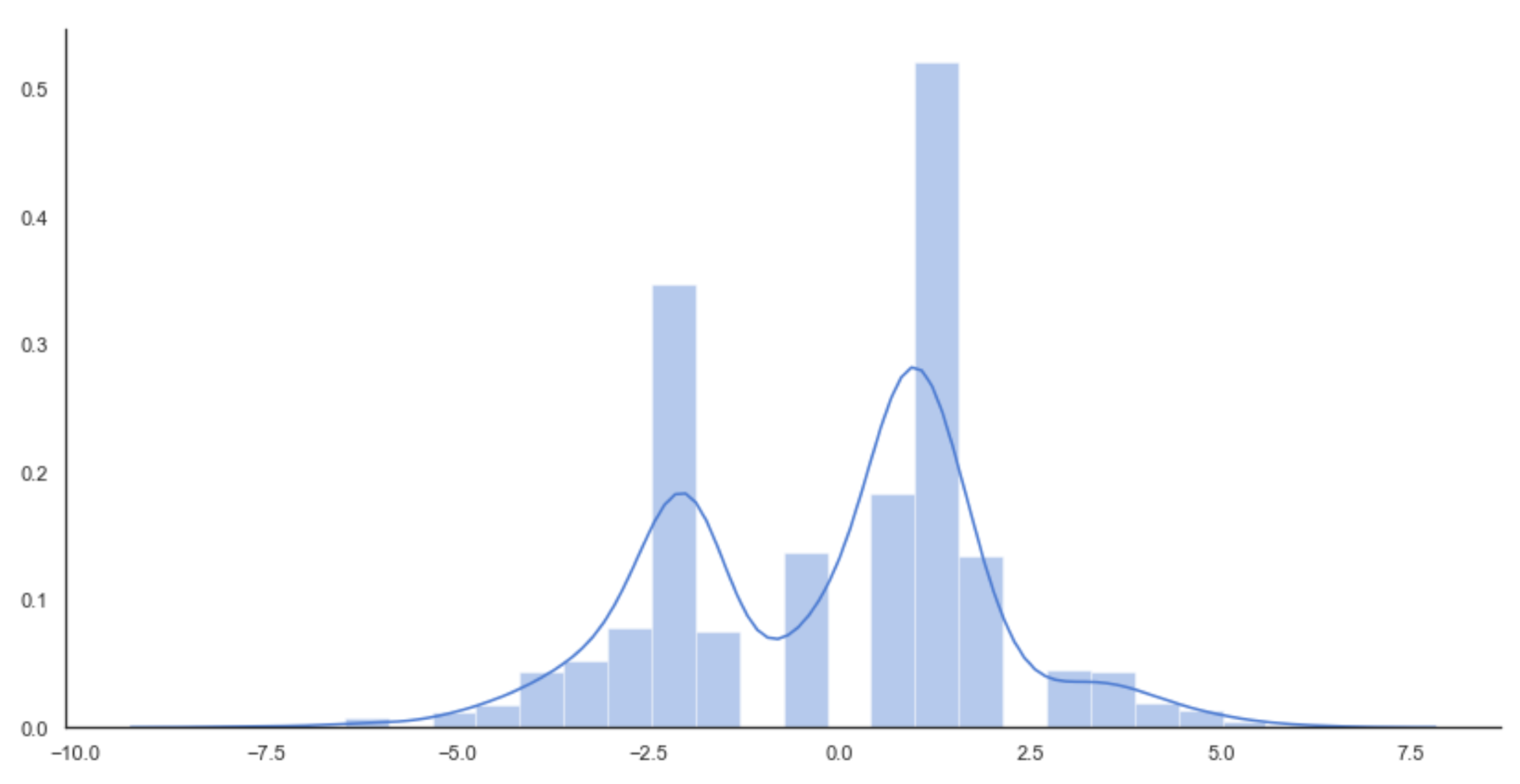
If the training set hasn't been sampled in a perfectly uniform way or it's partially unbalanced (some classes have fewer samples than the other ones), or if the model is prone to overfitting, the result can be represented by an inaccurate distribution, as follows:
Learned distribution
In this case, the model has been forced to learn the details of the training set until it has excluded many potential samples from the distribution. The result is no more Gaussian, but a double-peaked distribution, where some probabilities are erroneously low. Of course, the test and validation sets are sampled from the small regions not covered by the training set (as there's no overlap between training data and validation data), therefore the model will fail in its task providing completely incorrect results.
In other words, we can say that the variance is too high because the model has learned to work with too many details, increasing the range of possibilities of different classifications over a reasonable threshold. For example, the portrait classifier could have learned that people with blue glasses are always male in the age range 30–40 (this is an unrealistic situation because the detail level is generally very low, however, it's helpful to understand the nature of the problem).
We can summarize by saying that a good predictive model must have very low bias and proportionally low variance. Unfortunately, it's generally impossible to minimize both measures effectively, so a trade-off must be accepted.
A system with a good generalization ability will be likely to have a higher bias because it is unable to capture all the details. Conversely, a high variance allows a very small bias, but the ability of the model is almost limited to the training set. In this book, we are not going to talk about classifiers, but you should perfectly understand these concepts in order to be always aware of the different behaviors that you can encounter while working on projects.