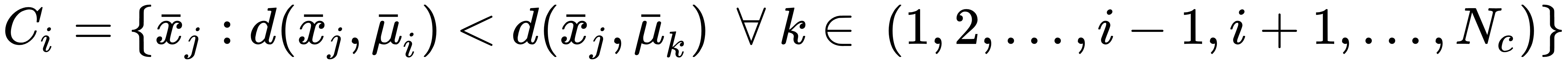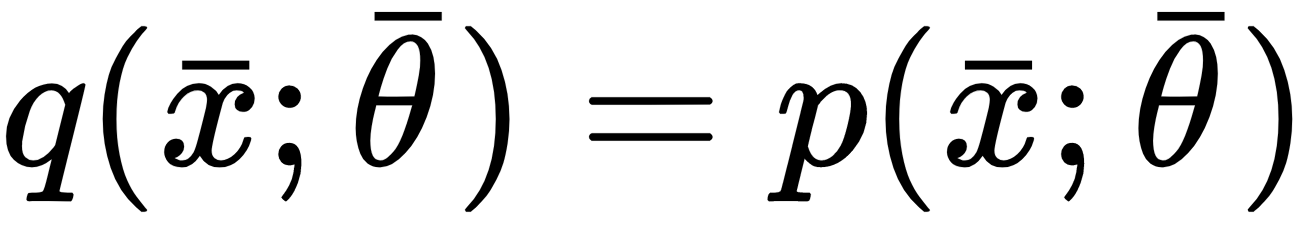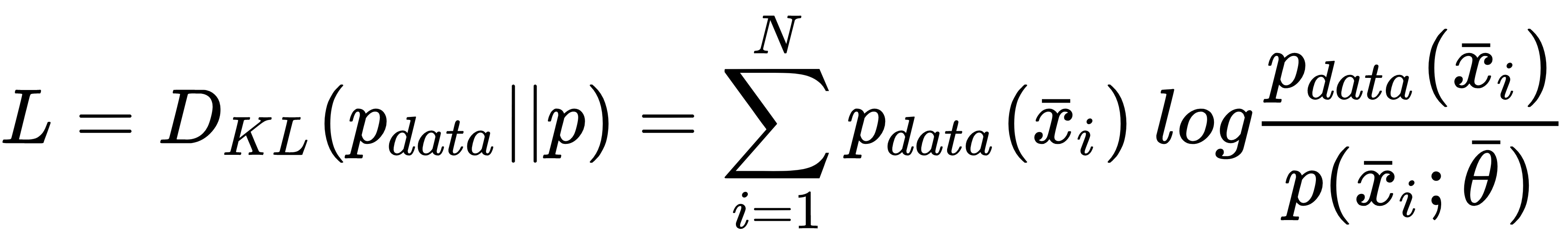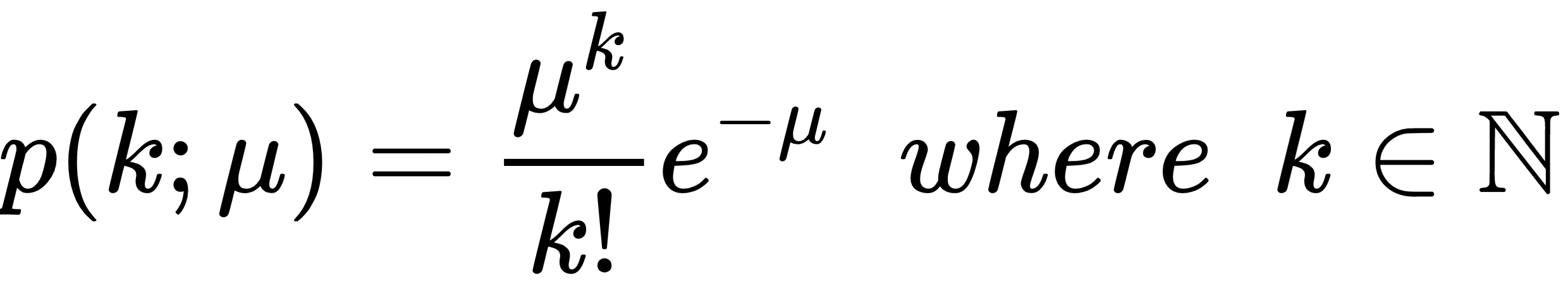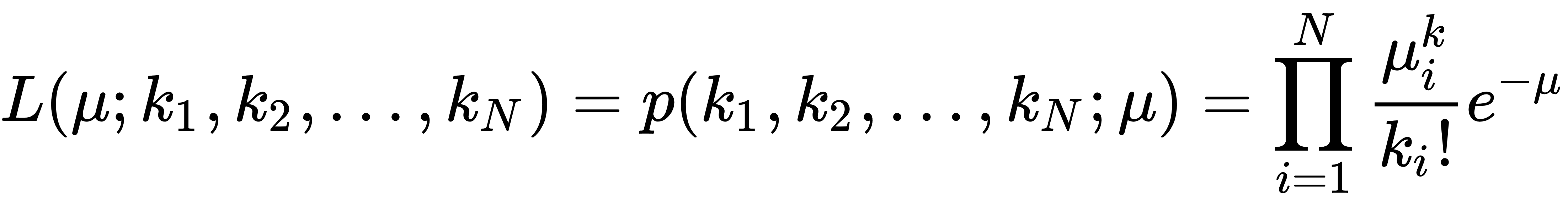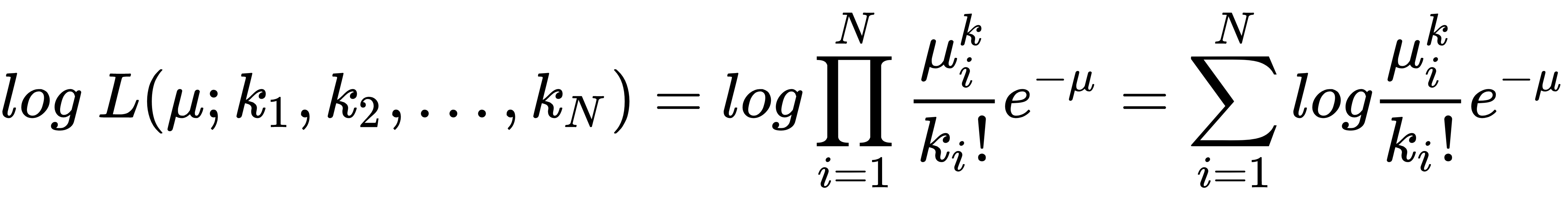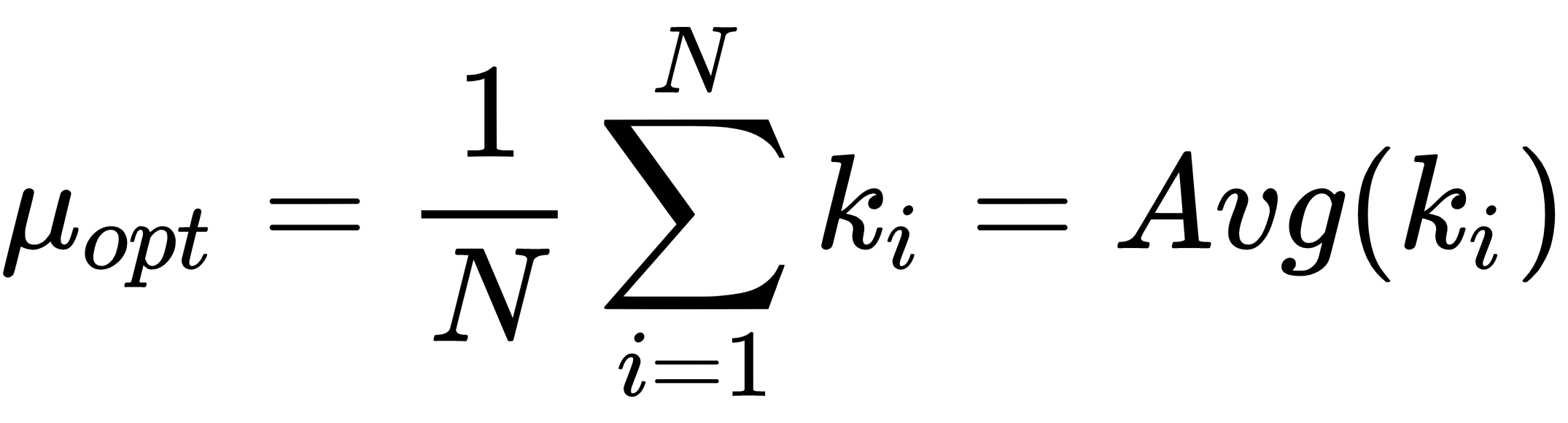At this point, we can briefly introduce the different types of machine learning, focusing on their main peculiarities and differences. In the following sections, we'll discuss informal definitions followed by more formal ones. If you are not familiar with the mathematical concepts involved in the discussion, you can skip the details. However, it's highly advisable to study all unknown theoretical elements, as they are fundamental to understanding the concepts analyzed in the next chapters.
-
Book Overview & Buying

-
Table Of Contents

Hands-On Unsupervised Learning with Python
By :
Hands-On Unsupervised Learning with Python
By:
Overview of this book
Unsupervised learning is about making use of raw, untagged data and applying learning algorithms to it to help a machine predict its outcome. With this book, you will explore the concept of unsupervised learning to cluster large sets of data and analyze them repeatedly until the desired outcome is found using Python.
This book starts with the key differences between supervised, unsupervised, and semi-supervised learning. You will be introduced to the best-used libraries and frameworks from the Python ecosystem and address unsupervised learning in both the machine learning and deep learning domains. You will explore various algorithms, techniques that are used to implement unsupervised learning in real-world use cases. You will learn a variety of unsupervised learning approaches, including randomized optimization, clustering, feature selection and transformation, and information theory. You will get hands-on experience with how neural networks can be employed in unsupervised scenarios. You will also explore the steps involved in building and training a GAN in order to process images.
By the end of this book, you will have learned the art of unsupervised learning for different real-world challenges.
Table of Contents (12 chapters)
Preface
 Free Chapter
Free Chapter
Getting Started with Unsupervised Learning
Clustering Fundamentals
Advanced Clustering
Hierarchical Clustering in Action
Soft Clustering and Gaussian Mixture Models
Anomaly Detection
Dimensionality Reduction and Component Analysis
Unsupervised Neural Network Models
Generative Adversarial Networks and SOMs
Assessments
Other Books You May Enjoy
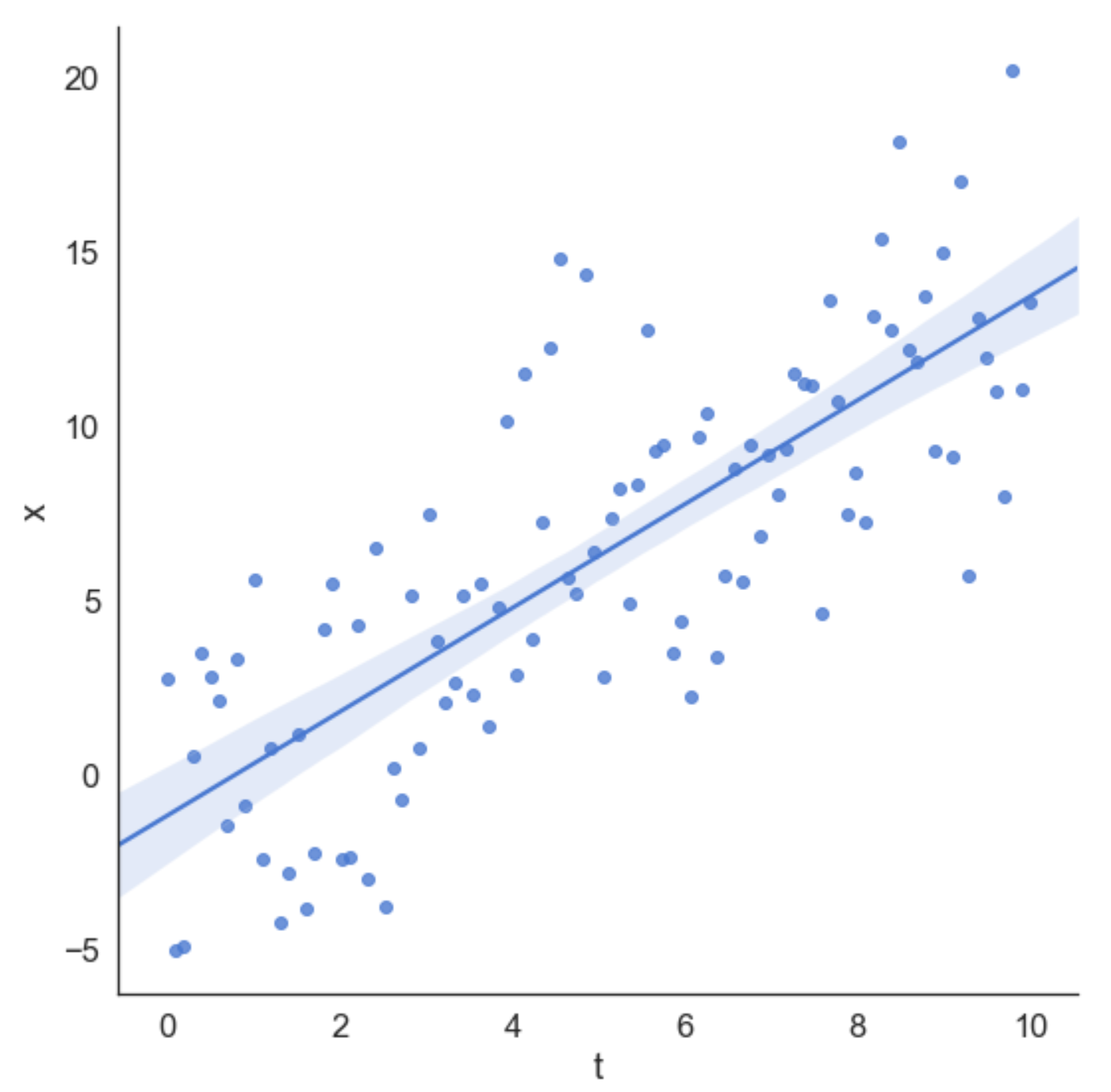
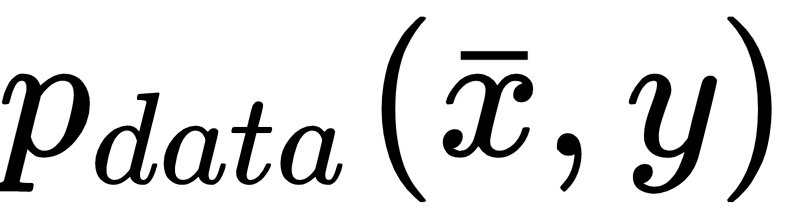 the dataset is obtained as:
the dataset is obtained as:
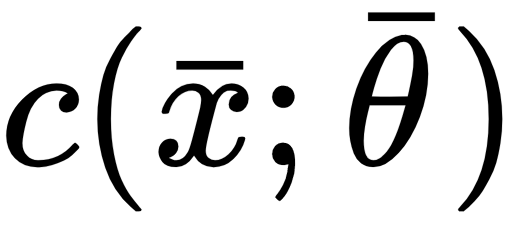 can be modeled in two ways:
can be modeled in two ways: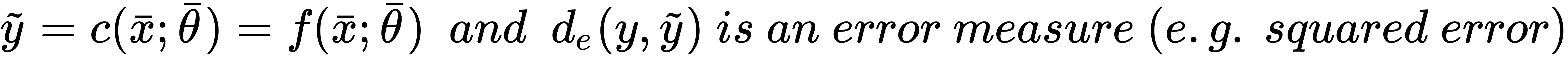
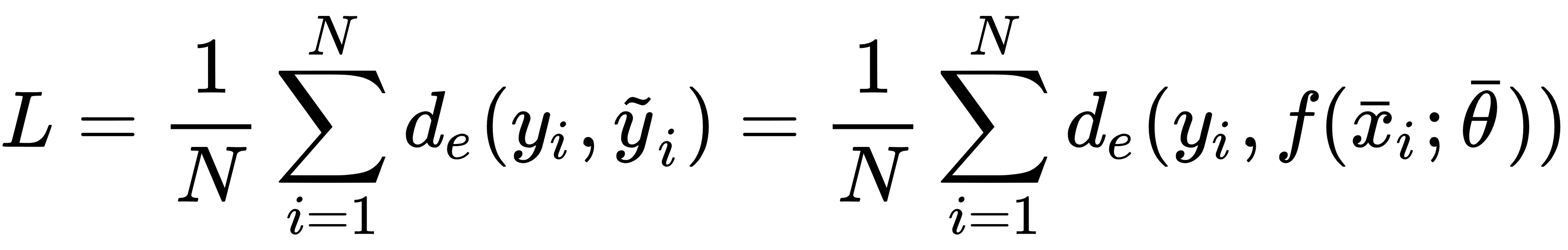
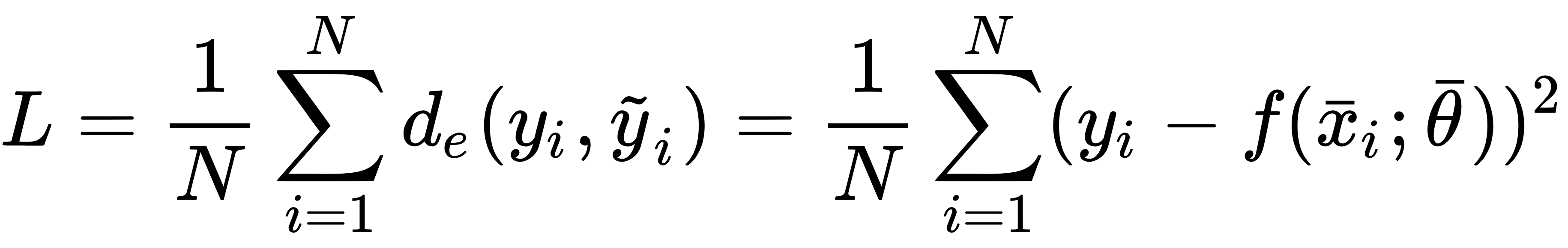
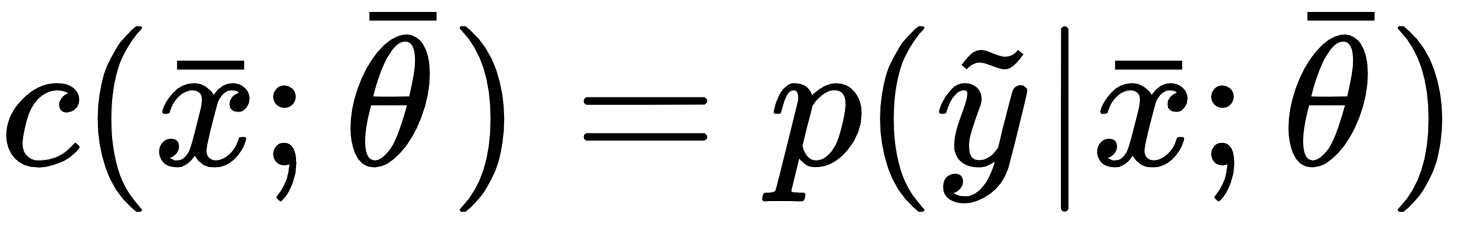
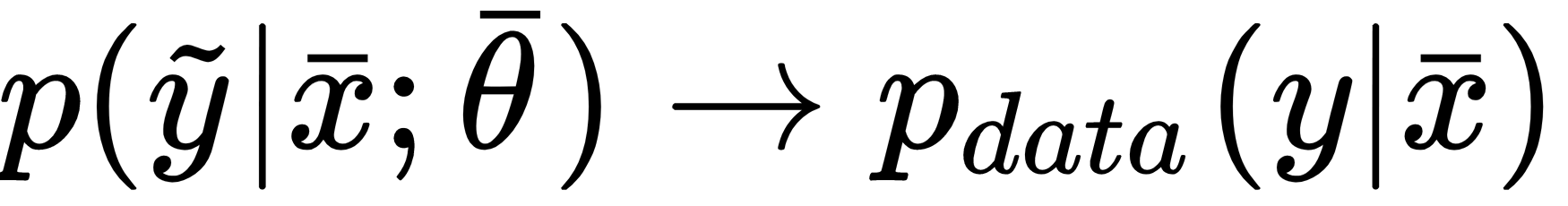
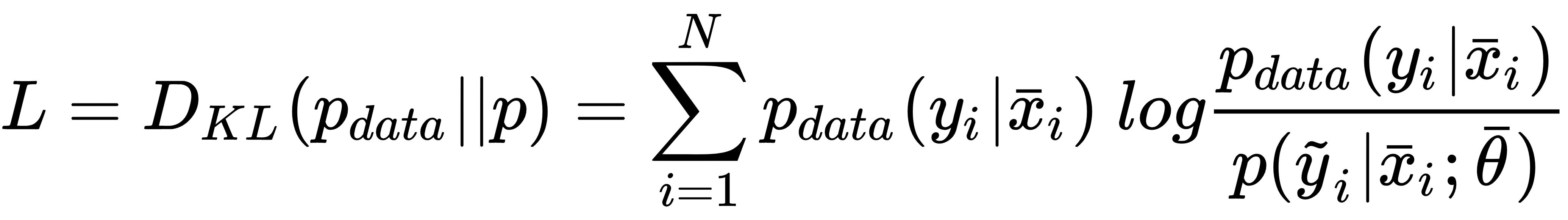
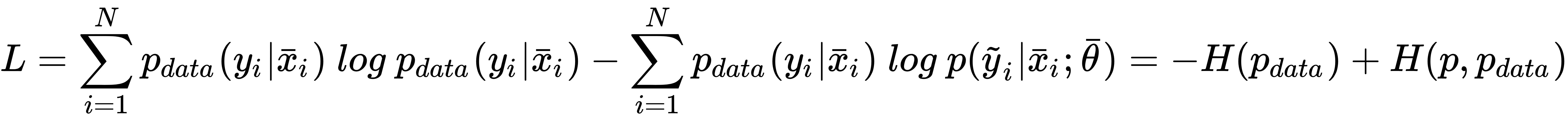
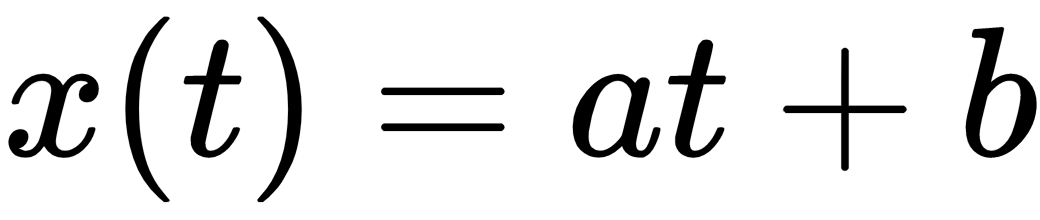
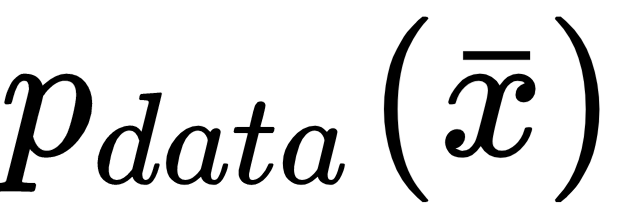 and we define the dataset X as:
and we define the dataset X as: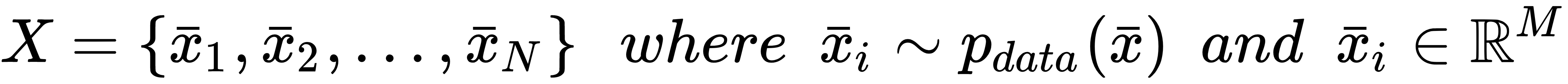
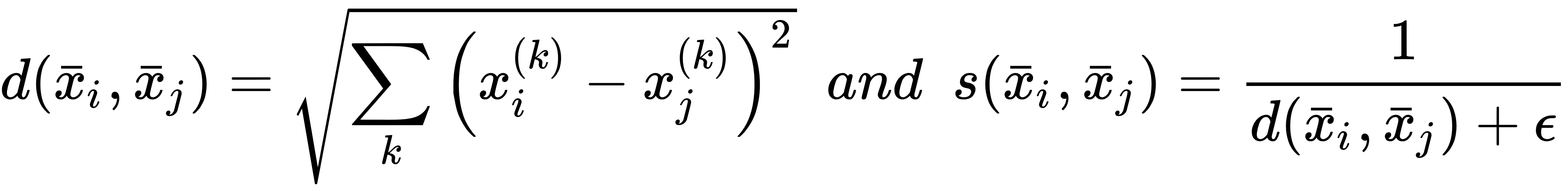
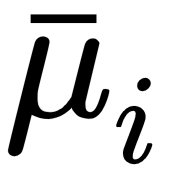 , we can create the set of assigned vectors considering the rule:
, we can create the set of assigned vectors considering the rule: