In the previous sections, we introduced some of the popular classical machine learning algorithms. In this section, we'll talk about neural networks, which is the main focus of the book.
The first example of a neural network is called the perceptron, and this was invented by Frank Rosenblatt in 1957. The perceptron is a classification algorithm that is very similar to logistic regression. Such as logistic regression, it has weights, w, and its output is a function, 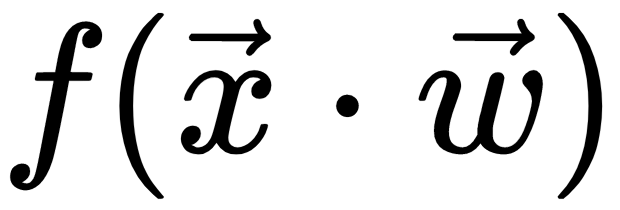 , of the dot product,
, of the dot product, 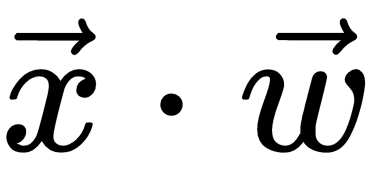 (or
(or 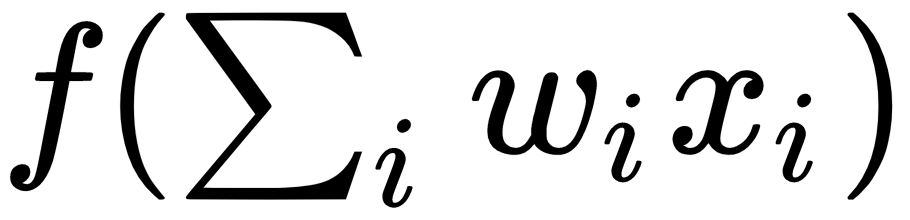 of the weights and input.
of the weights and input.
The only difference is that f is a simple step function, that is, if 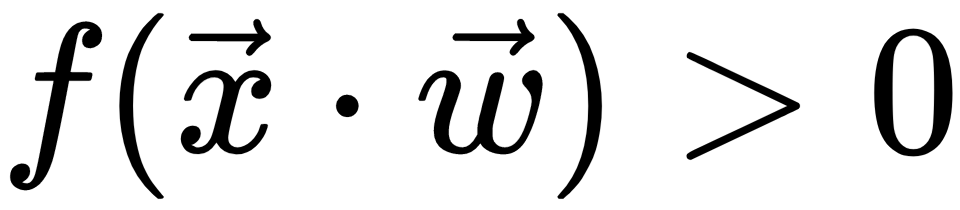 , then
, then 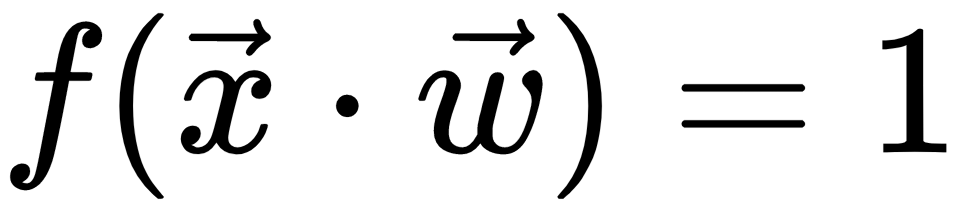 , or else
, or else 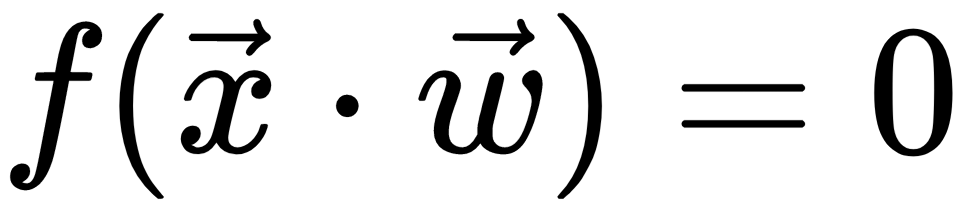 , wherein we apply a similar logistic regression rule over the output of the logistic function. The perceptron is an example of a simple one-layer neural feedforward network:
, wherein we apply a similar logistic regression rule over the output of the logistic function. The perceptron is an example of a simple one-layer neural feedforward network:
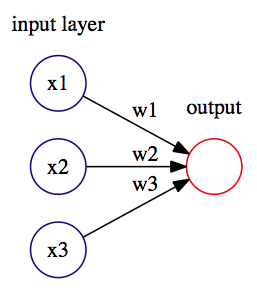
The perceptron was very promising, but it was soon discovered that is has serious limitations as it only works for linearly-separable classes. In 1969, Marvin Minsky and Seymour Papert demonstrated that it could not learn even a simple logical function such as XOR. This led to a significant decline in the interest in perceptron's.
However, other neural networks can solve this problem. A classic multilayer perceptron has multiple interconnected perceptron's, such as units that are organized in different sequential layers (input layer, one or more hidden layers, and an output layer). Each unit of a layer is connected to all units of the next layer. First, the information is presented to the input layer, then we use it to compute the output (or activation), yi, for each unit of the first hidden layer. We propagate forward, with the output as input for the next layers in the network (hence feedforward), and so on until we reach the output. The most common way to train neural networks is with a gradient descent in combination with backpropagation. We'll discuss this in detail in chapter 2, Neural Networks.
The following diagram depicts the neural network with one hidden layer:
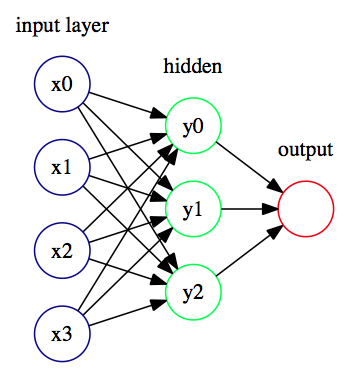
Think of the hidden layers as an abstract representation of the input data. This is the way the neural network understands the features of the data with its own internal logic. However, neural networks are non-interpretable models. This means that if we observed the yi activations of the hidden layer, we wouldn't be able to understand them. For us, they are just a vector of numerical values. To bridge the gap between the network's representation and the actual data we're interested in, we need the output layer. You can think of this as a translator; we use it to understand the network's logic, and at the same time, we can convert it to the actual target values that we are interested in.
The Universal approximation theorem tells us that a feedforward network with one hidden layer can represent any function. It's good to know that there are no theoretical limits on networks with one hidden layer, but in practice we can achieve limited success with such architectures. In Chapter 3, Deep Learning Fundamentals, we'll discuss how to achieve better performance with deep neural networks, and their advantages over the shallow ones. For now, let's apply our knowledge by solving a simple classification task with a neural network.