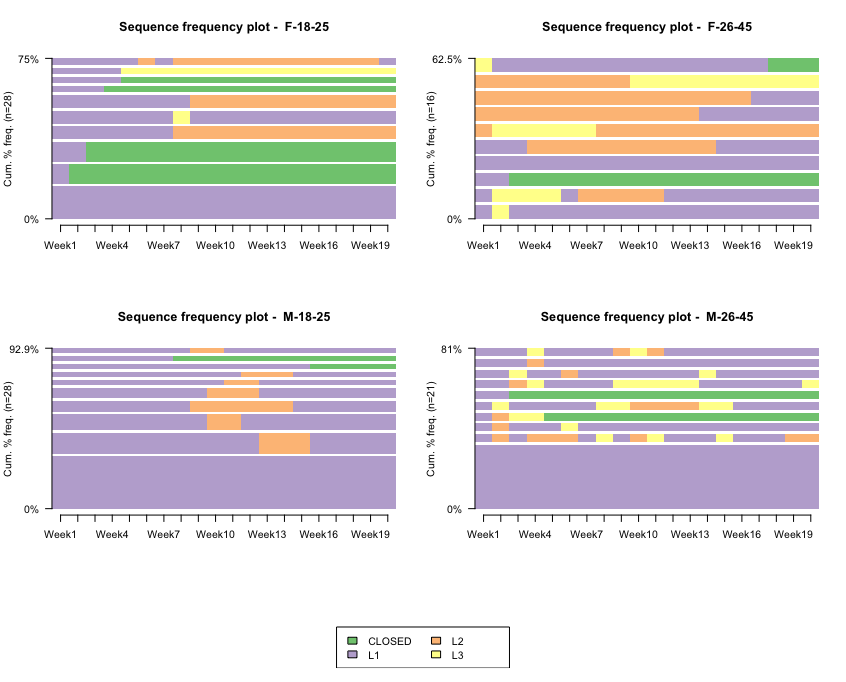
The TraMineR package allows us to work with categorical sequences, to characterize them, and to plot them in very useful ways. These sequences arise in a multiplicity of situations, such as describing professional careers: university→Company A→unemployed→Company B, or for example when describing what some clients are doing—opening account→buying→closing account.
In order to work with this package, we typically want one record per unit or person. We should have multiple columns—one for each time step. For each time step, we should have a label that indicates to which category that unit or person belongs to, at that particular time. In general, we are interested in doing some of the following—plotting the frequency of units at each category for each time step, analyzing how homogeneous the data is for each time step, and finding representative sequences. We will generally be interested in carrying these analyses by certain cohorts.